1 前言
路由本身并不是vue中内置的内容,而是它的一个插件,插件的基本使用方法也在上一章给大家介绍了一下。
它的作用在于,让你即使只写一个页面,也能写出多页面网站的效果。
其官网为:Vue Router
如果你重新用命令npm create vue@latest来初始化一个新的vue项目时,就有这个选项:

如果你选择了它,那么你生成后的项目就会显得有些不一样。
不过为了让大家更好理解,这里我还是直接在老项目中添加这个路由插件,一步一步的来看看它是如何使用的。
首先在原本没有添加路由功能的vue项目中,先安装路由插件:
npm install vue-router@4
命令哪来的?可以去看官方文档:安装 | Vue Router (vuejs.org)

安装完成后:

我们就可以将其添加到vue项目中了,还记得怎么添加插件吗?不会的到前面章节复习一下。
不过它与一般插件还有点不一样,因为它需要我们自己先通过一些函数创建路由对象:

比如这里,我是直接在main.js文件中完成的。
首先最前面,需要导入这个库中的两个函数:
createRouter:用于创建一个路由实例。createWebHashHistory:用于创建路由形式,这里的意思是使用hash模式,后面我们会继续深入。
然后就是开始导入组件,这个没什么可说的,自己随便写两个有一定区别的组件即可,没有任何影响。
紧接着就是定义一个路由数组,这个数组中每个元素都是一个对象,而每个对象都必须要有两个属性:
path:也就是路径,/代表根路径,/about就代表根目录下的about路径,如果你了解linux系统,就会发现这种写法和linux系统是一致的。component:也就是这个路径要对应的组件,一旦浏览器显示了path所保存的路径,就会将这个组件展示到页面上。
有了路由数组,那就可以调用函数createRouter来创建一个路由了,它的参数是一个对象,主要有两个重要的属性:
history:使用哪种模式的路由,主要有两种,这里用的是hash模式。routes:路由数组,也就是前面我们刚创建的那个。
通过这个函数得到的返回值,就是创建好的路由对象,然后就可以使用了:
app.use(router);
这就是一个路由的创建全过程。
而想要使用,我们还需要两个标签:
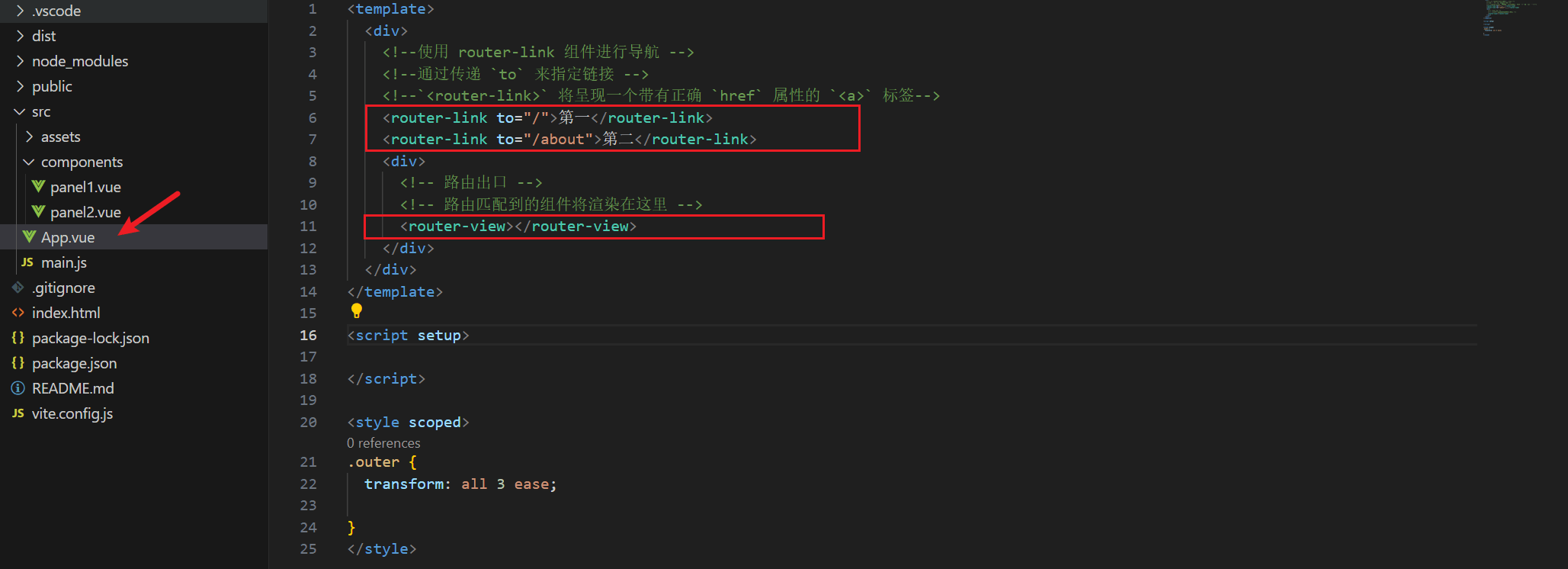
比如这里,我是在App.vue中使用的,你只需要将router-view标签放在你想要展示其它组件的地方,然后用router-link来切换浏览器的路由即可。
切换的方式就是写上to属性,里面写上当用户点击它,要切换的路径,也就是前面我们写在main.js文件中的那个路由数组。
比如这里,就实现了一个简单的、类似于菜单的功能:
- 通过点击第一、第二这两个标签,切换浏览器上的路由。
- 然后下面的
router-view标签就会根据浏览器的路由变换,来显示这个路由所对应的组件。
我这两个面板组件只有两个字符串而已:
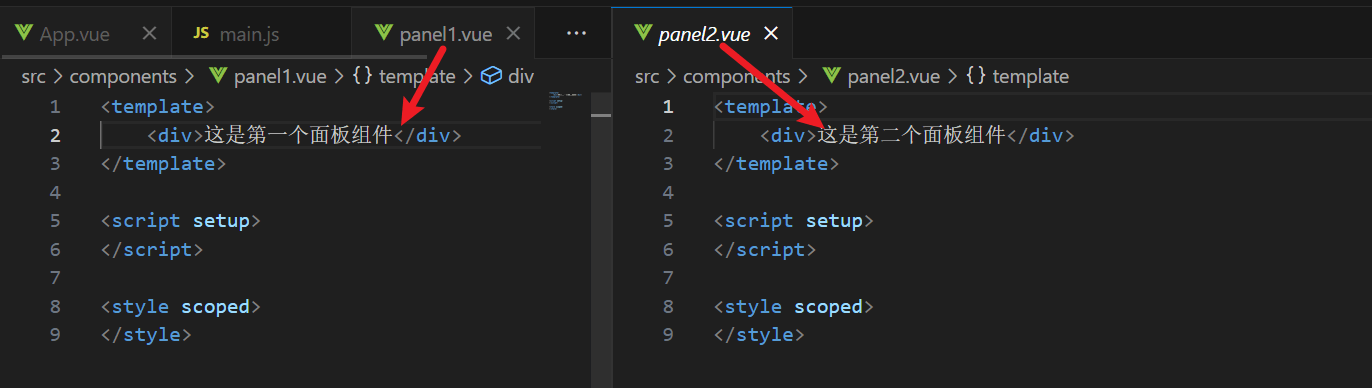
然后启动项目:

其默认是在根目录/,所以其默认就显示的第一个面板中的内容。
前面的router-link在底层会被转换为a标签,也就这里的第一、第二。
而当我点击第二这个标签时,你就会发现浏览器上方的路径发生了变化,也就是前面代码中写的那样。
并且注意,此刻页面的内容同样发生了变化,开始展示第二个组件的内容了!
可以看到,这里的路由有一个#,不是很好看,而这就是hash模式下的路由,后面我们会使用web模式下的路由,其观感就和普通页面路由一样了。
这就是路由的基本用法,简单总结一下:
- 首先定义路由数组,目的是完成路由与组件的映射关系。
- 然后使用函数
createRouter,根据路由数组来创建路由对象。 - 最后通过
use函数,使用一下这个对象,就完成了初始化工作。 - 使用的时候,
router-view标签的位置,会被动态替换为当前路由所映射的组件内容。 - 切换路由,可以通过
router-link标签,添加to属性完成。
2 规模化
上面是为了让大家更好的理解,所以我代码直接写在了main.js中,并且切换的页面组件也直接写在了components文件夹下。
在简单的项目中这样做当然没问题,但一旦项目的代码量变大,这样做很容易出现代码文件混乱的情况。
毕竟路由出现的目的,其实就是为了在单页面中写多个页面的,既然是页面,自然与普通组件分开存放比较合理。