1 前言
PE是Portable Executable File Format的简称,它是Windows系统上主要的可执行文件格式。我们常看到的.exe、.dll等程序,就是这种格式的。
PE格式也有32位与64位的区别,但64位并没有引入新的结构,只是简单的将原本的32位字段扩展为了64位而已。
一个PE文件的结构大致如下图:

注意是从下往上看的。
2 基本概念
PE格式的文件本身也是一个文件,和你看到的.txt文件是一样的,同样存储在硬盘上,并且就放在一个.exe文件内。
所以很自然的我们就可以得出结论,我们在代码中写的所有代码与数据,都会被统一按一定格式放入这一个文件中。
放在一起就很容易出问题,比如你解析的时候,这都是一堆二进制数据,你怎么知道这是代码还是数据呢?
所以PE格式的作用就出现了,它会将不同类型的数据存放在不同的块中,也就是上图的Section,也被称为区段、节等。
为了方便解析,每个块的大小都是页大小的整数倍,这里的页大小是当前系统分配的,我们不用管,其目的是为了提高系统检索数据的速度。
也正因如此,各个块之间是首位相连的,因为它们占用的大小实际上就是占用多少个页大小,比如页大小为4kb,那么它们的开始位置与结束位置都很容易被计算出来。
同时为了能够判断出某个区块中数据是什么类型,每个区块都会进行记录,比如该区块是否包含代码,是否只读,或者可读可写。
然后当你双击这个可执行文件时,系统就会按照其存储的顺序,将其载入内存中去:

正如上图所示,它并不会直接将其复制进内容,而是会调整一下各个区块的大小后,再填入内容,至于各个区块之间多出来的数据,则会用0填充。
这样做的原因是硬盘的页大小与内存的页大小并不完全相同,为了提高速度,内存的页大小比硬盘的页大小要大。
所以总体看上去,就是将原本的数据‘拉伸’了一下,但数据本身并没有发生变化。
一般PE文件被载入内存后,就被称为了模块(Module),而模块句柄,实际上就是文件被载入内存后的起始地址。
在编程中,我们可以通过这个句柄访问其内存结构数据,而这个起始地址,也被称为基地址(ImageBase)。
在代码中,我们可以通过函数GetModuleHandle来获取指定名称的模块句柄,如果传入NULL,则是获取当前可执行文件的模块句柄。
值得注意的是,虽然这个起始地址,也就是基地址会有一个默认的地址,一般为0x400000h,而dll一般会被默认加载到地址0x10000000h,但这个地址是可以被改动的。
所以一般我们逆向数据的时候,并不会去寻找某个数据、函数的具体地址,而是会去找它相对于基地址偏移了多少。
比如一个数据的地址为0x401000h,那么此时它偏移基地址的距离为0x1000,那么这个偏移的地址才是我们需要记录的。
因为基地址无论怎么变,我们都可以直接通过一些函数拿到,然后就可以通过这个偏移地址来计算出数据的真实位置。
这个相对地址,或者说是偏移量,就被称为:RVA(Relative Virtual Address),即相对虚拟地址。
与之对应的则是RAW(raw offset)或者说File offset,即物理地址,也就是你直接用十六进制编辑器打开一个可执行文件,看到数据的地址就是它的文件偏移地址。
3 PE格式
从前面的图可以看出来,PE格式是由很多部分组成的,所以下面我们就来简单介绍一下各个部分的作用。
3.1 MS-DOS
最前面的就是这个MS-DOS头部,这是远古时期的产物了,对于我们分析32位、64位程序来说,只用的到它内部的两个结构:
e_magic:标识这是一个dos头,固定为‘MZ’e_lfanew:指向PE头的位置
在vs中我们可以直接使用这个结构体:
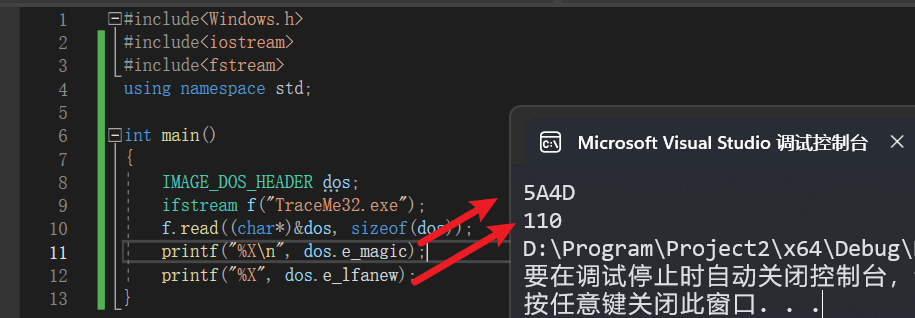
这里的IMAGE_DOS_HEADER结构体就是DOS结构体,我们这里直接将文件头读取到这个结构体对象中,然后打印出来这两个属性。
由于这是用的是十六进制打印,MZ两个字母对应的就是这两个十六进制数字:5A、4D。
而下面的110则是将要介绍的PE结构体的开头所在位置。
我们直接通过十六进制编辑器打开这个文件,也能直接找到这两个数据:

这里存在顺序的问题,由于是小端序,高位放在高地址,低位放在低地址,所以5A放在4D后面,01放在10后,转换成数字之后你需要自己将其转换一下,而在代码中,编译器会自动将其转换,所以无需我们手动操作:
#include<Windows.h>
#include<iostream>
#include<fstream>
using namespace std;
int main()
{
IMAGE_DOS_HEADER dos;
ifstream f("TraceMe32.exe");
f.read((char*)&dos, sizeof(dos));
printf("%X\n", dos.e_magic);
printf("%X", dos.e_lfanew);
}
3.2 PE头
PE头才是我们研究的重点,上面的DOS头如今一般只是用来定位这个PE头位置的。
当操作系统执行PE文件时,也是通过imageBase+dosHeader->e_lfanew计算得到PE结构所在位置的。
#include<Windows.h>
#include<iostream>
#include<fstream>
using namespace std;
int main()
{
ifstream f("TraceMe32.exe",ios::binary);
f.seekg(ios::end);
int len = f.tellg();
f.seekg(ios::beg);
char* buf = new char[len];
f.read(buf, len);
//上面将数据全部读取buf内
IMAGE_DOS_HEADER* dos = (IMAGE_DOS_HEADER*)buf; //更改其访问方式
int pe_pos=dos->e_lfanew; //得到PE格式的位置
IMAGE_NT_HEADERS32* pe = (IMAGE_NT_HEADERS32*)(buf + pe_pos);//得到PE结构
}
大致逻辑如上:
- 为了方便,直接将可执行文件全部以二进制的方式读入到buf中。
- 然后直接通过强制转换,修改其访问方式,得到PE结构的位置。
- 然后就可以通过加上这个位置,再一次强制转换,得到PE结构体
IMAGE_NT_HEADERS32
这里是32位的,如果是64位。则结构体名称为IMAGE_NT_HEADERS64,但其内部结构都是完全一样的,仅仅只是位数不同而已。
按住Ctrl,鼠标左键点击这个结构体,就能来到它的定义:

它内部有三个属性:
Signature:标识PE结构的开头,默认为‘PE00’,十六进制为:0x00004550FileHeader:这又是一个结构体,包含了PE文件的一些基本信息。OptionalHeader:虽然从名字中可以看出这是一个可选的结构,但实质上里面一般都包含了很多关键数据,一般需要将第二第三个属性联合起来分析才能得到完整的数据。
这两个结构体很复杂,这里只简单带大家过一下,如果想要更深入研究的自信可以查看官方文档:
首先是第一个:

Machine:该可执行文件的目标CPU类型,不同CPU用到的指令骑机器码不同。NumberOfSections:区块数量,也就是前面提到的Section。TimeDateStamp:文件创建时间和日期。PointerToSymbolTable:指针指向符号表的位置,主要用于调试。NumberOfSymbols:符号表中符号的个数。SizeofOptionalHeader:下一个结构体OptionalHeader的大小。Characteristics:文件属性
然后是第二个,更复杂了:

但还是简单过一遍:
Magic:标志MajorLinkerVersion:链接器主版本号MinorLinkerVersion:链接器次版本号SizeOfCode:所有含有代码的区块大小SizeOfInitializedData:所有初始化数据区块的大小SizeOfUninitializedData:所有未初始化数据区块的大小AddressOfEntryPoint:程序执行入口的RVABaseOfCode:代码区块起始RVABaseOfData:数据区块起始RVAImageBase:程序默认载入到内存中的基地址SectionAlignment:内存中区块的对齐值FileAlignment:文件中区块的对齐值MajorOperatingSystemVersion:操作系统主版本号MinorOperatingSystemVersion:操作系统此版本号MajorImageVersion:用户自定义主版本号MinorImageVersion:用户自定义次版本号MajorSubsystemVersion:所需子系统主版本号MinorSubsystemVersion:所需子系统次版本号Win32VersionValue:保留字段SizeOfImage:载入内存后的总大小SizeOfHeaders:MS-DOS头、PE头、区块表总大小CheckSum:校验和Subsystem:文件子系统DllCharacteristics:显示DLL特性的标志SizeOfStackReserve:初始化时栈的大小SizeOfStackCommit:初始化时实际提交栈的大小SizeOfHeapReserve:初始化时堆的大小SizeOfHeapCommit:初始化时实际保留堆的大小LoaderFlags:与调试相关,默认为0NumberOfRvaAndSizes:数据目录表的项数DataDirectory:数据目录
这里最后的数据目录又是一个结构体,而且还是一个数组,它用于指向输出表、输入表、资源块等资源,保存其所在的地址与大小:

这个数组一直都默认是16,分别对应于下面的数据:

这些数据都是可以直接通过工具分析出来的:
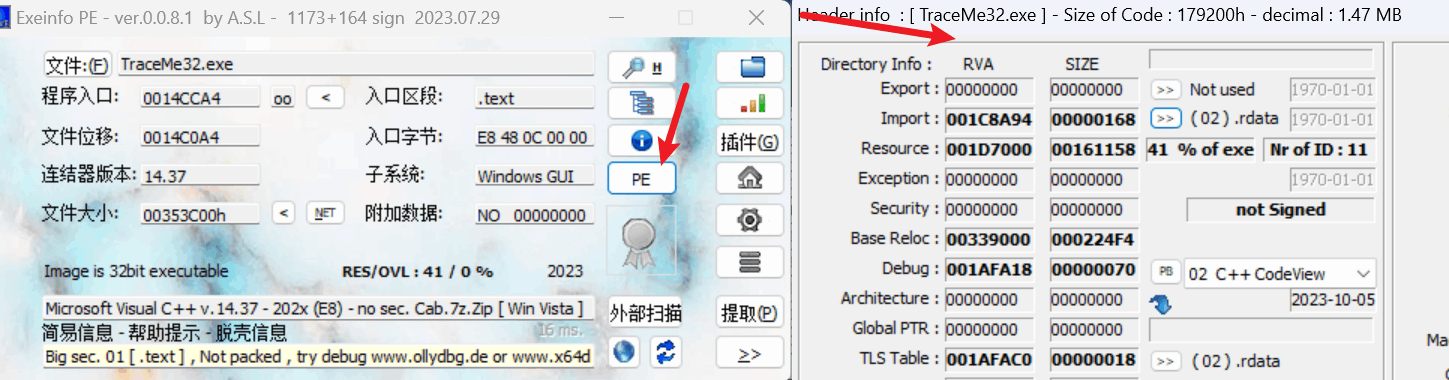
3.3 区块
区块是由区块表索引的,区块表紧跟PE文件头之后,在PE头与数据之间,区块表中包含每个块的实际信息,指向区块实际位置,结构体为:IMAGE_SECTION_HEADER
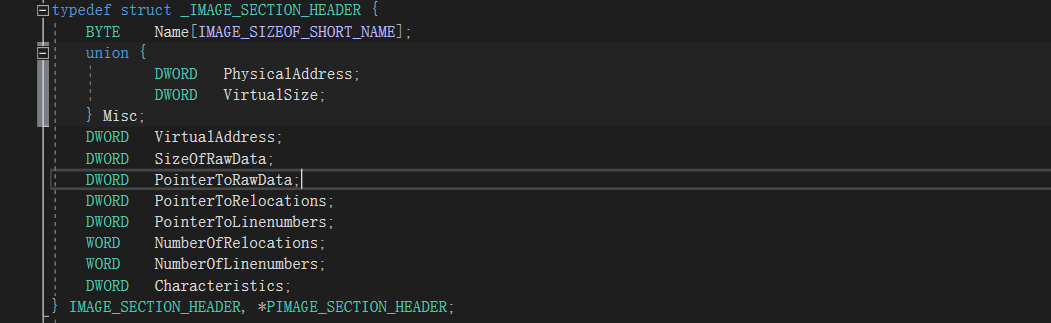
Name:块名VirtualSize:实际被使用的区块大小,即对齐前的大小VirtualAddress:这个块被载入内存后的RVA,是按内存页进行对齐的。SizeOfRawData:该块在磁盘中所占的空间。PointerToRawData:该块在磁盘文件中的偏移。PointerToRelocations:在exe中无意义PointerToLinenumbers:该块在行号表中的行号数目。Characteristics:块属性,比如代码、数据、只读、可写等等
正因为这些都有固定的格式,所以是可以直接通过工具分析出来看到的:

PE文件中至少会有两个块,一个是代码块,另一个则是数据块,每个块都有其特定的名字。
比如上图中的.rdata,就代表这是一个只读r的数据块data。
.text就是其默认的代码区块,.data则是可读可写的数据块,全局变量、静态变量一般都会放在这里。
.rsrc是资源,包含了程序所有用到的图标、菜单、位图等等资源,只读的。
.reloc是可执行文件的基址重定向,一般用于DLL中。
甚至你可以自己命名区块,在vs中通过这样的指令完成:
#pragma data_seg("MY_DATA")
不过一般不怎么做,都是默认即可。
关于区块另一个重要的点就是对其,为了方便解析,区块一般都是需要进行对齐的,比如200为对齐值,如果你的数据只有150,那么你依旧会被分配200的大小,这样方便找到各个区块的边界。
而对齐又分为磁盘对齐、内存对齐两种,系统一般有默认值,编译时会将默认值编译进PE文件头的两个属性中:
FileAlignment:定义了磁盘区块的对齐值,一般为200hSectionAlignment:定义了内存中区块的对齐值,一般为1000h
正因为这两个值不同,所以同一块数据放在磁盘与内存中的相对偏移量也就会不同,这就涉及到了换算。
但数据相对于本区块的偏移量是不变的,所以就很好计算了,首先通过工具得到各个区块在内存、在文件中的范围:
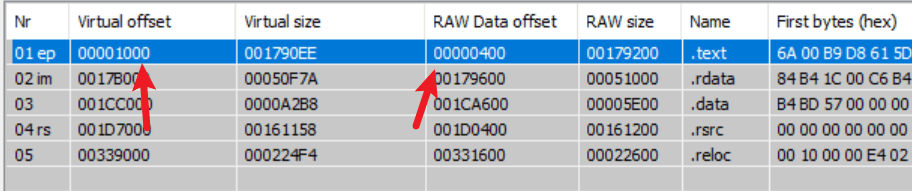
假设一个数据在内存的地址为:1100,那么就是在第一个区块.text内部1000-1790EE,那其物理地址自然就是400+100=500了。
3.4 输入表
可执行文件使用其它Dll中的代码或数据的过程就被称为输入,在PE文件被载入时,WIndows最工作之一就是定位所有被输入的函数和数据,并让可执行文件可以使用它们。
而这个过程就是通过PE文件中的输入表完成的,也被称为导入表。
可以通过前面提到的工具PE信息中查看到:
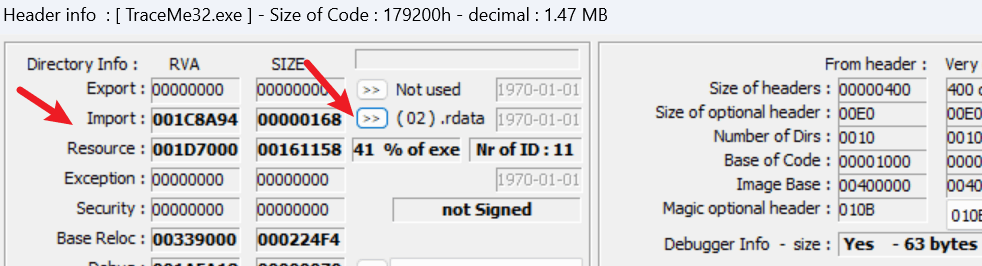
点击它后,就会列出所有该可执行文件将要导入的dll了:

如果想要在程序中分析,基本过程如下:
- 通过前面PE结构中可选头最后一项得到输入表位置与大小。
- 该输入表是一个
IMAGE_IMPORT_DESCRIPTOR结构的数组,最后以0结束,从这个数组中就能拿到上面这些信息。
然后就可以从每个结构体中查询到该dll中将要导入的函数、数据,过程如下:
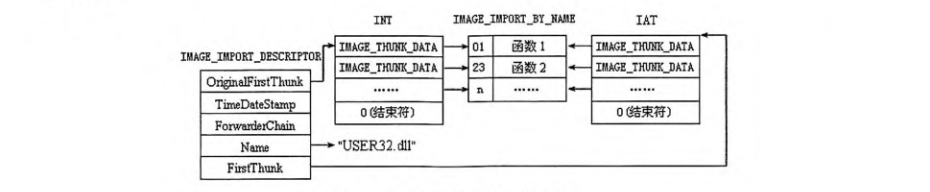
这里不再赘述具体过程了,反复套娃,比较麻烦,且很多人可能对此过程其实也并不感兴趣,我们可以通过一些工具很方便的完成这些功能。
输出表的逻辑与这里差不多,只不过是用来分析dll的,即导出函数,同样可以通过工具直接获取,这里不再赘述的,有兴趣的可以看看书。
3.5 基址重定位
基址重定位是一个比较关键的技术,前面说过,exe一般默认会被加载到40000h位置处,由于它就是进程的创建者,自然没人跟他争。
但dll不一样,一个exe一般会加载很多dll,而dll默认都在1000000h处,这就会产生矛盾,而为了解决这个矛盾,就出现了基址重定向的技术。
它的做法就是将本程序中所有可能需要被修改的地址都放在一个数组中,比如其原本定义的全局变量,按理来说地址就应该是不变的,但考虑到基址有可能会被重定向,那就会将它的地址放在在一个数组中。
那么当系统将其加载到其它地址时,也就能从这个数组中重新计算出新的地址了:

上图就是其链接器是想要加载到0x400000处的,但实际上却被加载到了0x870000处,那么上图中原本两个存入在重定向表中的数据就会被重新计算位置。
这个表存放的区块便是前面提到过的.reloc中。
这一过程是自动发生的,一般来说我们只需要知道有这么一个过程即可,如果想要研究其原理的可以参考书籍。
3.6 资源
资源结构非常复杂,同样许多数据结构不断套,形成了一个树状结构:
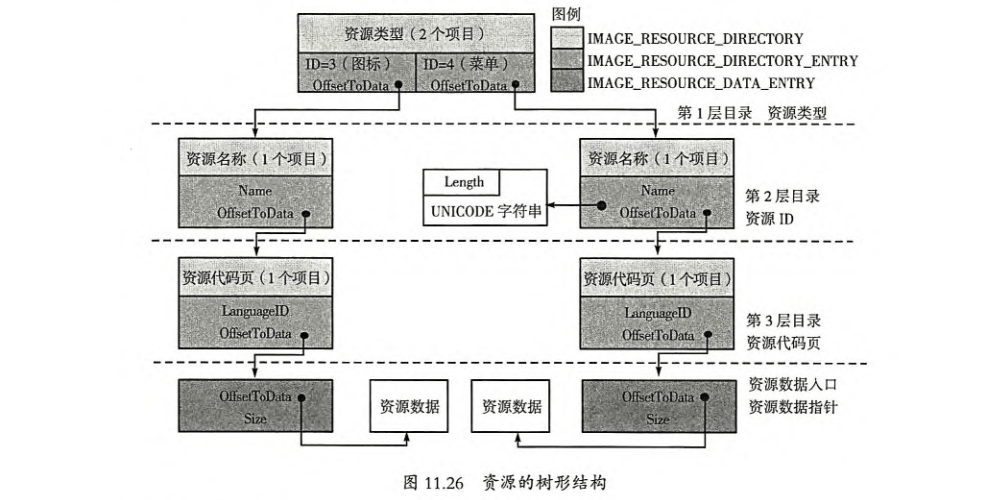
这里不再赘述,有兴趣的可以去看书籍,这里推荐一个工具:Resource Hacker,它可以允许你直接编辑这个资源数据,非常强大。