一、前言
多线程路径在很多语言中都是绕不开的话题,原因无它:可以提高程序执行效率。
如果不理解线程的,可以先看看下面这两篇文章:
本文重在实践,也就是如何用rust开发多线程程序,以及一些注意细节,并不会再过多讨论相关的概念。
二、启动新线程
在rust中启动新线程是一件很简单的事情,下面直接用一个例子进行说明:
fn main(){
let t=std::thread::spawn(||{
println!("这是一个新线程");
});
let _ = t.join(); //等待线程执行结束
}
上面的代码很简单,就是单纯的用std中的thread中的spawn函数创建一个新线程去打印一个字符串,但由于主线程结束会自动终止其它线程的执行,所以我在后面调用了其上的join函数来等待新开的线程执行结束。
注意,符号
_在rust中意思等同于“忽略”,在这里的意思就是不需要返回值,同时可以屏蔽rust编译器的警告。
spawn函数的作用就是新开一个线程并执行传递进来的函数,这里函数我写的是闭包形式,当然你也可以写一个独立的函数:
fn main() {
let t = std::thread::spawn(new_thread_fun);
let _ = t.join(); //等待线程执行结束
}
fn new_thread_fun() {
println!("这是一个新线程");
}
上面这两段代码是完全等价的,不过为了少写一个函数名,大部分人一般都更乐意用闭包,所以一定要习惯这种写法,后面文章中也会对其进行详细介绍。
rust中的闭包其实和C++中的lambda表达式差不多,其它语言基本都有类似的写法,后面章节会对其做更详细的介绍。
同时spawn函数新建线程后,还会返回一个实例,该实例可以将其理解为就是我们刚才新建的那个线程。
如果我们需要等待那个线程执行结束再执行后面的代码,那就可以调用其上的join函数。
这个join函数应该还是很常见的,基本各种语言中等待线程执行结束都用的这个名字,其本意是‘加入’‘合并’,也就是合并执行流的意思,等待子线程执行流执行结束合并到主线程。
如果你将多线程运行比喻为多条河流,那么调用join函数处就是两条河流的合并位置。
三、所有权
安全是rust语言首要的任务,多线程环境又是最容易引起数据竞争问题的地方,因此rust对于线程也做了相当多的限制,为的就是保证多线程对于数据访问的安全。
而首先要提到的就是所有权问题,看一个例子:

上面这种情况应该是最常遇到的,也就是我想要在新开的线程中使用外部的变量。
但这样做肯定是有问题的,因为一旦你新线程内访问修改它,外面的线程也访问修改它,就会造成数据不一致的、数据竞争的问题。
而rust对此的解决方案就是直接通过move关键字,将你新线程内使用到的变量所有权从外部移交到新线程内,这样不就只能新线程这一个线程使用了吗?
此时只有一个线程能使用变量了,也就自然不会存在所谓的数据竞争问题了:

通过在闭包之前添加move关键字,就会将其所有权移交到新线程内部,因此外面自然也就无法再继续使用了。
四、共享数据
虽然上面这种移交所有权的方式确实安全了,但在很多时候却是不符合我们所希望的。
至少就我自己平时开发而言,大多数开线程都是希望其执行一些繁重耗时的任务,并将其结果保存、或者就存储到某个变量上,然后我在主线程中来取。
但这种移交所有权的方式是无法得到任何线程执行后的结果的,所以此时我们就需要让多个线程共享数据,而不是移交所有权。
最简单的方式就是使用Arc:
fn main() {
let str = "hello www.kucoding.com".to_string();
let d = std::sync::Arc::new(str);
let d1 = d.clone();
let t = std::thread::spawn(move || {
println!("{:?}", d1.as_ptr());
});
t.join().unwrap();
println!("{:?}", d.as_ptr());
}
注意,对于控制多线程访问的方法、工具,官方都将其放到了std::sync中,比如这里的Arc便是。
Arc的意思是原子引用计数,其中“原子”的意思是它本身内部计数值不存在多线程访问安全问题,因为它已经是最小执行单位了,只有执行与不执行这两种情况,因此它本身是线程安全的。
然后这里我通过Arc的new函数实例化一个Arc变量,传入的参数则是需要让它管理的数据,也就是我们这里这个字符串。
紧接着关键一步来了,我通过其上的clone函数又克隆了一个Arc对象,并且在新线程中使用的也是克隆后的Arc对象。
let d1 = d.clone();
let t = std::thread::spawn(move || {
println!("{:?}", d1.as_ptr());
});
通过前面提到的所有权移交,此时新线程使用的是克隆得到的Arc对象,而本线程使用的则是最初的Arc对象。
注意:通过Arc封装后的数据大部分情况下并不影响其原本类型的使用。
所以这里在Arc实例上调用的as_ptr函数实际上依旧是其管理的String上面的函数,目的是获取该字符串所在内存的地址,也就是C/C++中常提到的指针。
此时打印结果如下:
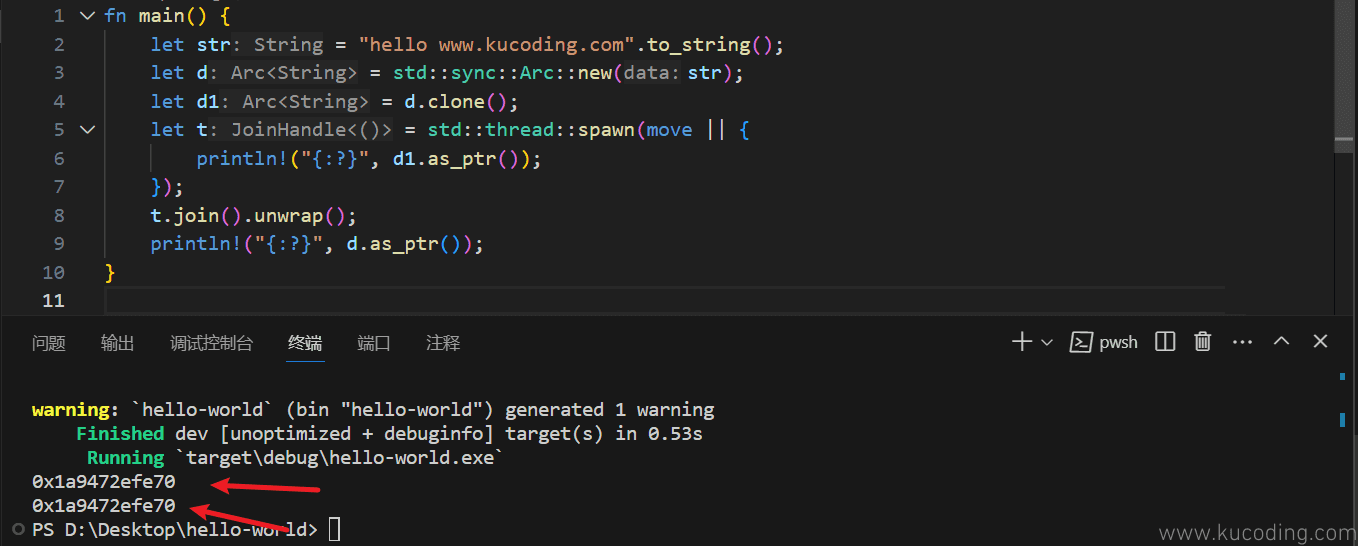
是不是有点神奇的感觉?明明前面我们都克隆了,怎么此时两个线程中打印的两个字符串的地址还相同呢?
地址相同,自然就意味着这两个实际上依旧还是同一个字符串了。
而这就是Arc的解决方案,它的实现原理大概如下:
Arc内部会保存一个计数,一般就是一个整数,它记录的是当前其管理数据的引用计数,比如这里通过new函数构造Arc对象并管理数据,此时引用计数就是1。