一、前言
虽然通过前文的基本使用,我们已经能够完成一个最基本的编辑器功能了,但离我们想要实现一个完全自定义的编辑器道路依旧很远。
想要实现这一点就需要将ProseMirror中的各种理念与细节理解明白。
首先第一个核心概念就是Schema,前文我们用到的是其官方给出的一个最基本的Schema来创建的一个编辑器,而本文,我们就要开始自定义一个Scheme。
二、理解Schema
想要使用好它,第一步就是理解它,Schema英文本意为模式、概要等意思,在这里我们可以将其理解为规则。
比如我们在前文中看到,其编辑器内部默认会创建一个p标签来接收我们按键输入的文本,但如果你用过浏览器原生的contenteditable属性,就会知道其默认的行为其实是生成一个div标签来接受用户输入。
这便是一个规则,并且这个规则是由我们前文使用的官方提供的schema所规定的。
但仅仅这样依旧还是不够,我们还需要知道我们可以控制的规则有哪些。
空洞的讲述这些概念是很难理解的,所以我这里直接以本系列教程的目标为例,也就是制作一个Markdown编辑器,来设定这个规则,我相信在这里过程中你会将其理解的更深入。
三、自定义Schema
此时我们就可以用到前文我们所没有用过的model模块了,因为Schema类型就被定义在该模块中。
想要实现一个自定义的Schema,那么第一步就是用该类型来实例化一个自定义的Schema:
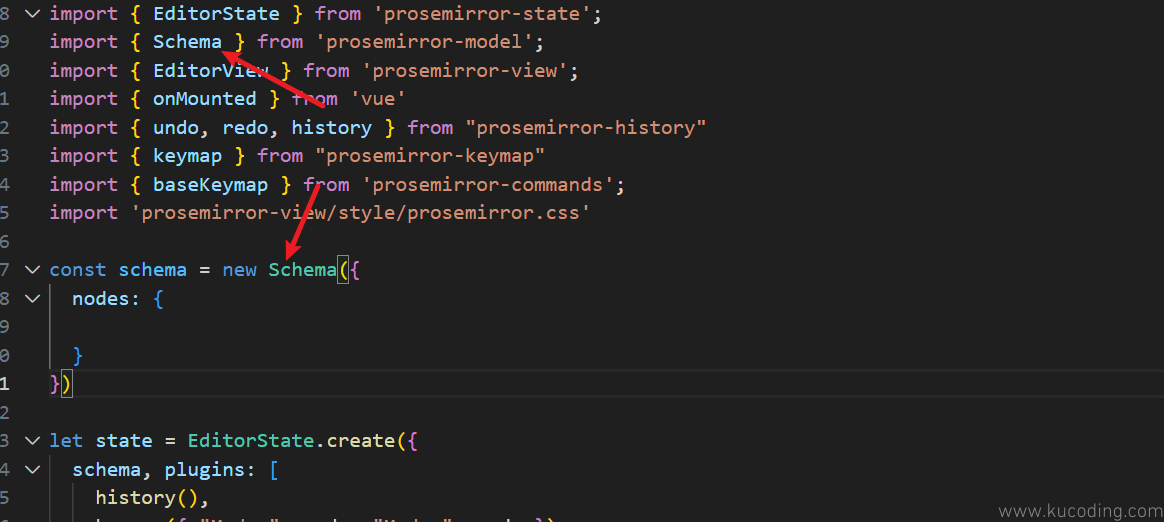
它的构造函数参数为一个对象,该对象里面最重要的一个属性就是nodes,我们就是通过它来构造规则的。
除此之外它还有两个属性,分别为
marks与topNode,这个我们后面再提。
从我的写法来看,也知道该属性依旧是一个对象,我们接下来就是按照顺序、从上到下来依次书写该结构、也就是文档规则。
实际上就是不同节点之间的包含关系,同时每个节点都是一个NodeSpec对象结构:
const schema = new Schema({
nodes: {
doc: { content: "paragraph+" },
paragraph: { content: "text*" },
text: { inline: true },
}
})
注意最顶层的node必须为doc,这是其默认的配置项,代表整个编辑器文档,也就是document,然后它的内部有一个content属性,代表着它能包含哪些内容。
比如这里我用的是paragraph+,也就是一个或者多个paragraph,这是正则表达式的规则。
而paragraph就是我们第一个所定义的,它的内部为text*,代表0个或多个text,也就是文本内容。