一、前言
如果你学过任何一门编程语言,我相信你对生命周期都应该是不陌生的,不理解的可以先看一看:常量与变量。
这个概念很通用、同时也很简单,所以这里就不过多赘述了。
生命周期带来的一个问题就是:一旦脱离了变量的生命周期,那么继续使用该变量所代表的内存就是一个危险的行为。
虽然rust通过“所有权”概念的引入,让代码变量很安全了,但要注意:rust中也是支持变量引用的。
比如:

引用写法和C++类似,都是通过&完成,这在rust中的String与所有权中我们已经有所见识了,只不过当时用的是&str。
上图就是一个典型的实例:变量本身的生命周期比其引用变量的生命周期要短。
变量
x在超出本代码块后就会被清除,那么外面r变量对其进行的引用就显然是不对的。
但此时我们可以发现,rust编译器非常的智能,可直接识别出这种错误。
而它识别的原理就是通过为所有变量添加“生命周期注解”、再通过其内部的“借用检查器”来确保引用是有效的。
大部分情况下这一过程我们是无需操心的,但在某些情况下,编译器无法判断时,就需要我们自己亲手为变量添加“生命周期注解”了。
比如下面这段代码:

该函数的作用是返回长度更长的那个字符串,此时其返回值可能是x、也可能是y,这取决于传入的参数。
并且由于x、y两者都是引用类型,并不拥有内存,这导致编译器在编译期间就无法确定该函数返回值的生命周期,从而出现错误。
在这种情况下,我们就需要自己手动为其添加声明周期注解了。
二、生命周期注解
在了解、学习生命周期注解之前,我们必须要明白一个事实:我们只需要为“引用变量”手动添加生命周期注解。
这意味着对于拥有内存所有权的一般变量来说,我们是不需要、也不能为其添加生命周期注解的。
因为一般变量的生命周期规则很简单,就是其所在的代码块范围内,编译器自身就完全可以胜任,而无需我们去标注。
了解了这个基本事实后,我们就可以来看看生命周期注解的原理。
以开头那段代码为例:

假设变量r的生命周期为 'a,那么它的长度就是从其声明的位置一直到main后的{}结束,也就是该代码块的结束。
假设变量x的生命周期为'b,那么变量x的生命周期就是从其声明到该内部代码块结束的位置。
此时由于r变量为x变量的引用,但其生命周期居然比其引用的变量生命周期还长,这自然就报错了。
这便是rust编译器在编译代码时所做的事情:自动为每个变量计算生命周期,如果引用变量的生命周期比原变量生命周期还长,就报错、编译失败,从根本上杜绝不安全的行为。
但上面仅仅只是比较简单的情况,编译器能够自动为其计算生命周期,所以是不需要我们人工参与的。
而对于比较复杂的情况,比如开头提到的那个函数,编译器就无法确定了,这个时候就需要我们手动去标注生命周期注解了:
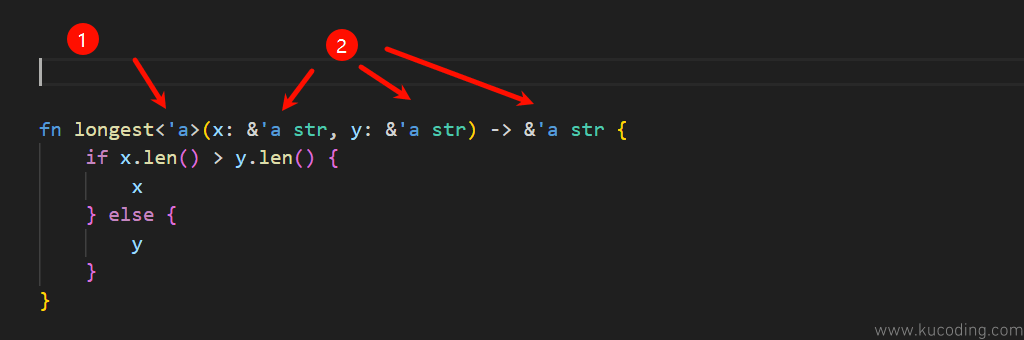
由于生命周期注解是编译器编译期间使用的,所以它用法和前面提到的泛型一样,是要通过在函数名后的<>中进行声明,然后才能在参数中使用的。