1 前言
经过前面一章小项目的洗礼,如果你真的是0基础,可能会有点怀疑人生的感觉。
所以本章节暂时不做项目了,而是将前面重要的知识点再深入讲解一遍,给大家讲讲有哪些坑,同时也会添加一些后面可能会用到的新知识点。
前面的章节中,我用到了一些东西,在当时为了不陷进去,并没有深究,所以首先我们先来将前面提到过的一些东西,在这里好好的理一遍。
2 强制类型转换
如其名字,也就是类型之间的转换,但是要强制进行,如果不强制进行,就不会转换。
首先来看为什么需要强制类型转换,以及强制类型转换到底干了一件什么事情。
现在来观察下面这段代码:
#include<iostream>
using namespace std;
int main() {
char c = '1';
cout << c<<endl;
cout << (int)c << endl;
}
运行结果为:
1
49
这是为什么?明明是同一个变量c,为什么通过强制转换,将char转换为int后,输出的值就不一样了呢?难不成强制类型转换还会改变变量的值不成?
但事实是,强制转换并没有改变任何值,它只是让编译器在解释这个字符c时的方式发生了变化。
前面我提过一嘴,我们所能看到的一切字符都是通过一张表给映射出来的,比如上面的代码就是通过ASCII码表映射出来的,更详细的内容可以查看:ASCII码表。
我们首先给字符变量c赋值了一个字符 ‘1’,但如果你用鼠标放在这个字符 1上 ,你就会发现一件神奇的事情:

其实这个字符‘1’,是数字49强制转换为而来的。
因为‘1’这个字符在ASCII码表中对应的数字就是49,计算机本身存储的仅仅只是数字而已,就算这里写的char类型,其本质上依旧只是数字。
唯一不同的地方在于输出,比如当cout看到这个数字是49,但由于它是char类型,所以就将其输出为了字符‘1’,而如果是int类型,那就会直接根据ASCII码表将其转换为字符‘49’,与数字本身的值相同。
比如:
int a=100;
double b=3.14;
如果像char那样,直接将数字映射为字符的话,输出int,就是一个字母,因为ascii码表中数字100对应的一个字母。
而double,这种小数因为没有映射关系,甚至没办法输出成字符到屏幕上让我们看到。
所以为了能够让我们直接能够输出100,都是需要将上面这些东西进行转换的。
比如数字100,先拆成 1 0 0三个字符,然后映射到ASCII表,分别代表数字 49 48 48,然后就可以直接根据这三个数字输出对应的字符了,也就能够输出我们在控制台上看到的100。
综上我们可以得知,所谓强制转换,就是一个东西本来是可以有多种解释方法的,但编译器默认了其中的一种解释方法,这时我们就能够通过强制类型转换,来强制编译器将它解释为另外一种意思。
在C/C++编程中,强制类型转换我们会经常用到,请务必理解其精髓:给目标换一种解释方式。
更底层的原理,你还可以参考本站的另一篇文件:数据类型。
3 输入输出
在C/C++的学习过程中,最重要的一块就是输入与输出,但C/C++在输入与输出这一块的坑那也是相当的多,且需要理解一些理念。
最常见的坑就是使用scanf时,变量前面必须带取址符&,但如果你要接受的是一个字符串又不用加,这是为什么呢?
这就是因为scanf是根据变量的地址来找内存的,所以变量就得取地址,而字符串属于字符数组,其名字就代表数组的起始地址,所以不用加:
char c;
char buf[30];
scanf("%c %s",&c,buf);
其次就是这些众多的控制符,实在让人望而生畏,所以有了c++中的cin,其目的就是为了简化这一步骤,它可以自己识别出变量的类型。
但cin也有缺点,那就是如果输入的东西很多,它就会变得很长,与cout一样,这就取决于你具体的使用场景了。
而C++中进行格式控制也会相比较于C要繁琐的多,比如要控制输出数字的宽度为5:
#include<iostream>
#include<iomanip>
using namespace std;
int main() {
printf("%5d\n",100);
cout << setw(5) << 100;
}
可以看到,用printf只需要在%d之间添加个5就行了,而C++还需要引入一个头文件iomanip,然后在输出的时候调用函数setw(5)。
还有更多的格式控制知识,只能大家自己在网上、平常使用中慢慢积累了。
接下来我要讲的是,输入输出中普遍使用的函数,比如前面我们用到的一个ssprintf_s函数,可以向字符数组中输出格式化好的字符串。
除了向字符数组,其实还有向文件中格式化输出的函数:fprintf_s。
这些函数后面带了一个_s的后缀,说明它是vs中相应的安全函数,如果你使用不带_s的函数,即当你使用以前的不安全函数,比如fprintf,那可能就会报错(这个函数不会报错,原因在下),除非你定义特定的宏禁止编译器报错。
那么为什么有些函数是安全的,有些函数被认为是不安全的呢?
这个的主要原因就是,不安全函数不会要求你填缓存区有多大。
比如ssprintf函数,你只需要填一个字符数组的名字进去就行了,但这个函数内部是不知道这个字符数组有多大的,如果你后面往里面东西加多了,就会越界,最终可能就导致程序直接挂了。
而安全函数主要就是解决了这个问题,当你需要填字符数组时,都会要求你在紧跟其后的一个参数填上这个字符数组有多大。
举个直白点的例子:
//scanf("%s", buf); //不安全函数,不会要求你传入这个缓存区有多大
scanf_s("%s", buf, 10); //安全函数,一般会需要你在紧随其后的一个参数中填入前一个缓存区的大小
使用安全函数时,这一过程并不会有提示信息,你得自己记住填入缓存区大小,如果不是缓存区,比如基本的int、double类型,也不用填大小。
所以对于那些本就不需要操作缓存区的函数,比如printf,其实就是无所谓的,虽然它也有相应的安全函数printf_s。
上面是C语言的格式化方法,分成了对字符数组、文件、控制台三种操作函数。
除了输出,当然还有对应的输入函数,看它们的名字规律,知道怎么写吗?(提示,将函数名中的printf替换为scanf即可)
C++同样提供了三种类对上面三种对象进行操作,分别为iostream,fstream以及strstream,用于格式化输入输出控制台,文件,以及字符数组(又称为缓存区)。
其中,我们经常使用的cin,cout是官方已经写好的对象,并且已经定向到了控制台,所以不用我们特地自己去写,可以直接用,而其它两种就需要自己定义使用了。
比如使用前面没用过的strstream:
#include<iostream>
#include<strstream>
using namespace std;
int main() {
char buf[100]{};
strstream s(buf,100,ios::out);
s << "https://www.kucoding.com" << " " << "余识"<<endl;
cout << buf;
}
其使用方法与文件操作非常相似,除了上面这种可以自己选择参数的,也有特定的类,比如istrstream,ostrstream专门用来输入与输出缓存区。
4 缓存区
所谓缓存区,就是申请一块内存,用来专门存数据的,因为char刚好只占一个字节,便于计算,所以我们一般都是用char字符数组当作缓存区。
但事实上如果你非要用int数组当缓存区,也同样可以,因为它们本质就是一块内存而已,怎么使用完全取决于你,C/C++就是这么的自由。
就像下面这样,两种写法本质上都是在申请100个字节大小的内存:
char buf[100];
int buf1[25];
一般来说,申请缓存区有两种方式:
char buf1[100];
char* buf2=new char[100];
delete[] buf2;
上面这两种方法都是可以的,区别仅仅是在使用上。
像第一种这样使用,如果出了所在的大括号,也就是生命周期结束,那么它的内存会被自动回收,之后就无法被使用了。
用官方语言来讲,它是在栈上申请的内存,而且你必须在使用的时候指定明确的数字,这称为静态申请。
栈是一种基本的数据结构,核心机制是后进先出,前面也简单提到过,C++对应的实现有stack。
而第二种方法,就是在堆上申请的内存,它的生命周围不再局限于大括号内部,只要你不delete它,那这块内存就不会被自动回收,而且你可以动态指定申请多少内存,这称为动态申请。
还有一点区别就是静态能申请的空间一般没有动态可申请的空间大。
虽然其底层的实现机制可能比较复杂,但核心区别就上面这几点。
就使用而言,你只需要记住它们之间的区别就行了。
当然,这里动态申请内存我是用C++的方式写的,你也可以用C语言的方式(malloc与free)。
这两者的主要区别在于对类的申请与释放上,C++会调用类的构造与析构,而C只申请内存,其它啥也不干。
更多细节可以学习这篇文章:内存分配。
5 运算符
运算符其实不难,特别是我们本来就经常使用的加减乘除等运算符,所以这里只讲解几个特殊、但又在编程中经常用到的运算符。
首先就是自增自减运算符,即++和--。
这两个本身的使用是很简单的,但耐不住总有人喜欢搞事情,比如非要写个++a+b++这种式子。
这实在没什么意思,毕竟前面我说过,小括号的优先级最高,如果非要写这种别人不容易看懂的式子,最好的办法就是加上小括号。
不同编译器对这类式子的处理方法并不完全相同,所以建议了解这两者的区别就好,没必要过于深入纠结。
如果将两个加号写在前面,则在表达式中自增运算符就会先算,算完之后再算其它表达式。
如果两个加号写在后面,就会先算完表达式,再自增1。
比如下面这段代码:
#include<iostream>
using namespace std;
int main() {
int a = 10;
int b = a++;
int c = ++a;
cout << b <<endl;
cout << c <<endl;
}
结果为:
10
12
能想明白怎么回事吗?其实很简单,由于第一句++在后面,所以先进行赋值b=a,得b=10,然后再自增1,此时a=11。
后一句,++在前面,所以a先自增1得到a=12,然后赋值c=a得到c=12。
自减运算符也是同理。
还有一个取反运算符,比较常用,但最开始使用可能有点想不明白,来看下面这段代码:
#include<iostream>
#include<strstream>
using namespace std;
int main() {
cout << boolalpha << true<<endl;
cout << boolalpha << !true;
}
其中boolalpha为格式控制,用于输出true与false,如果不加,就会输出1和0,结果为:
true
false
其实际效果就是取反而已,而我们最常使用的就是在判断语句中:
if(!表达式){
}
这种写法,相当于就是如果表达式为false,就执行。
最后还有或(||)与且(&&),这两个运算符主要是用来判断多个表达式的:
if(表达式1 || 表达式2 || 表达式3){ //任意一个表达式为true,就执行
}
if(表达式1 && 表达式2 && 表达式3){ //只有所有表达式都为true,才执行
}
需要注意的点是,这种程序计算机是挨个执行的。
比如上面有三个表达式,就会先执行表达式1,该表达式如果为false,那么在&&语句中,后面的表达式2和3就不会执行了,因为已经整体为false了。
但在||语句中,却还需要继续执行表达式2,因为目前还不能判断结果。
说这些话的目的是,将最有可能决定整体结果的表达式放在前面,就可以简化运算。
比如三个表达式中,如果表达式1和2几乎总是true,而表达式3很可能为false,那么在&&语句中,表达式3就应该放在前面,因为如果它为false了,那么后面两个表达式就不会进行计算了。
6 VS注释
看到这里你可能会想,注释有什么好讲的,不就两种写法,用于说明代码是干嘛的吗?
是的,注释确实很简单,但有时候你会发现,如果用这两种注释来注释函数,会相当不便携,因为别人怎么知道你这个函数的这些参数是干嘛的,应该填哪些?
所以这就引出了VS中又一强大的功能:自动注释。
比如我们现在有下面这个函数:
int Add(int a,int b) {
return a + b;
}
那么我们只需要在vs中该函数的上一行,连按三个/ ,VS就会帮我们自动生成注释:
/// @brief
/// @param a
/// @param b
/// @return
int Add(int a,int b) {
return a + b;
}
然后我们只需要在注释的后面,填写信息即可
/// @brief 用于计算两个数的和
/// @param a 加数1
/// @param b 加数2
/// @return 返回结果
int Add(int a,int b) {
return a + b;
}
brief:简要说明这个函数是干嘛的。param a:说明参数a是干嘛的,或者需要填什么。return:该函数返回值的说明。
然后当我们在使用这个函数时,就会弹出对应的提示信息:

当然,如果你觉得这个自动注释不好看,我们还可以换:
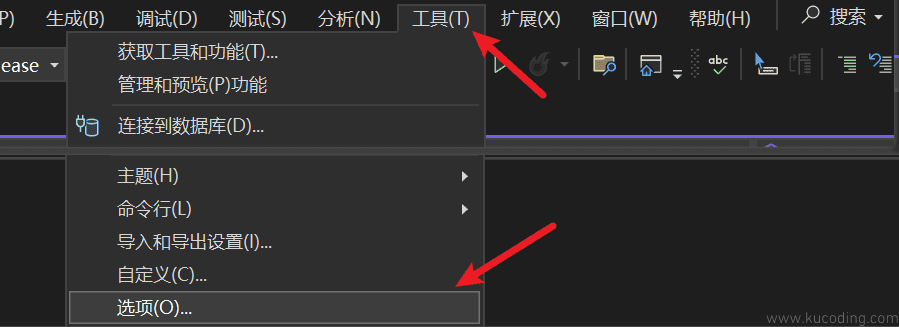
搜索注释,选择C/C++常规,选择批注样式就可以更换,比如我就更喜欢第二种:
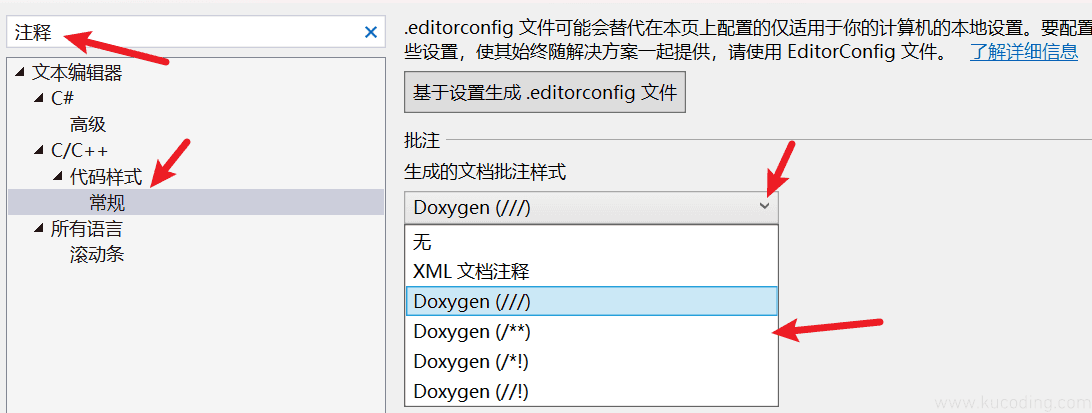
需要注意的是,当你选择其中任意一种注释方式,调用方法就变为其后括号中所展示的符号。
比如这里我使用第二种,就需要打下字符/**来进行注释了:
/**
* @brief
* @param a
* @param b