1 前言
经过前面两章对基础知识的再学习,我们其实就已经有了开发更高级项目的能力,所以本文就将详解一个爬虫的制作流程,尽量稳固一下前面章节所学的知识点。
爬虫大家应该都不陌生,基本可以说是python的专属领域,C/C++写爬虫怎么没听说过?
那确实是的,因为python方便简洁,有大量的爬虫库可以直接让你调用,但C/C++可就没这么好了,基本没有现成的爬虫库让我们调用。
所以用C/C++写爬虫的缺点很明显,那就是非常消耗我们的时间,但优点也显而易见,可以帮助我们稳固基础,因为是我们自己写爬虫的底层过程。
2 爬虫介绍
上面谈了这么多,可能一些同学还并不知道爬虫到底是个什么东西。
所谓爬虫只是形象之称,本质也只是一个程序而已。
当你用浏览器看到本页内容时,在本页内容中是不是还能许多可以跳转到其它页面的链接或者按钮?
当你点击这些链接或者按钮后,页面就会跳转到其它页面,这说明不同的页面之间都是相互关联的。
这些页面之间的联系就可以形象的看作一个网,而我们的程序就是利用了这张网,在各个页面之间游走,寻找自己所需要的资源,就很像在这张网上的虫一样,所以就称为爬虫。
上面的解释比较形象,大家应该是能够理解的,只是可能不知道的我们现在应该如何控制我们的程序在这张网上游走以及爬取数据罢了。
不过我既然将本文放在这里,就说明大家目前是已经有能力写出爬虫的,所以不用担心!
3 前置准备
在正式写代码前,我们还需要理解一下网页,以及本次爬取目标的分析过程。
前面我说过,程序员写的代码,需要通过编译器编译生成可执行文件,最后才能运行,对于拿到.exe可执行文件的我们来说,是无法看到程序员所写的源代码的。
但对于网页来说不一样,网页是运行于浏览器上的,换句话来说,网页的源代码是给浏览器看的,而现在浏览器就在我们的电脑上,网页源代码不可能是提前放到浏览器里面的吧?
对的,网页源代码,是我们通过网络下载到我们的电脑上,然后交给浏览器解析,最后呈现出我们所看到的网页。
那么下一个问题就是,我们应该如何找到网页源代码?
其实非常简单,直接点击F12即可,可能需要先点击功能键Fn进行启用:

然后我们就可以将源代码全选,复制下来,然后粘贴到记事本中:

保存,将后缀名改为.html:

然后双击它,浏览器就会将其打开:

此时我们就可以看到已经打开了这个网页,上面浏览器中的文件路径也为本地桌面文件的路径。
只不过由于本站用的是nuxt框架开发之后进行的编译,这样保存下来然后运行是很难看的,这个方面的内容大家如果有兴趣的话,可以参考本站前端相关的教程。
暂时看不懂网页源码也不用担心,相比于C/C++,这些都是相当简单的东西,我们只要会抓取关键信息即可!
有了源码,我们自然也就可以为所欲为了,比如图片以及各种数据,我们都能拿到手!
这次的目标网站是一个图片网站,试着爬取该网站上的图片:
http://www.netbian.com/
主页长下面这样:

先看一看该网页的源码,这次看点不一样的,点击F12,点击元素窗口:

其实这也是源代码,只是浏览器帮我们将源码整理了一下,更好看而已。
但只是这么看,也看不出什么来,所以我又用到了另一个工具,选择元素的工具:

先点击控制台左上角,就可以选择你想要观察的任何一个元素,比如上图中的一张图片,点击它,然后控制台元素窗口中就会自动给你找到这张图片的源代码是哪一段。
而且这段代码还特别整齐,当你试着用鼠标移动到这些代码上的时候,你会发现网页中的其它图片也标亮了:

这说明这些项 <li> 内容</li> 里面都包含了图片的源代码,结合我们目前看到的这个:
<li>
<a href="/desk/32698.htm" title="可爱小熊 开始等过年桌面壁纸" target="_blank">
<img src="http://img.netbian.com/file/2023/1201/small0043470z9wO1701362627.jpg" alt="可爱小熊 开始等过年桌面壁纸"><b>可爱小熊 开始等过年桌面壁纸</b>
</a>
</li>
上面代码是直接复制的一个 <li> 内容</li> ,可以看到,li里面的内容包含了一个链接,在img 后面的 src中,而且这个链接最后是以.jpg结尾的,这不就是张照片吗?
http://img.netbian.com/file/2023/1201/small0043470z9wO1701362627.jpg
访问这个链接试一试?
这不就是图片吗?所以我们的爬虫逻辑其实是非常简单的:
- 下载该页面的源代码。
- 从该页面的源代码中,提取符合条件的
<li></li>中的图片地址。 - 通过该图片地址将图片下载到本地即可!
4 爬虫编写
老规矩,建项目day8--crawler并设为启动项,新建main.cpp的源文件。
4.1 下载函数
首先是下载页面的代码,但由于我们目前还没有学网络编程,那就直接用别人写好的函数就好了。
该函数所在的头文件与库:
#include<Windows.h> //头文件
#pragma comment(lib,"Urlmon.lib") //链接包含该函数的静态库
官方函数定义:
HRESULT URLDownloadToFileA(
LPUNKNOWN pCaller, //用于显示下载进度,但需要继承COM接口,过于麻烦,可直接填0
LPCTSTR zURL,//填写要下载的地址
LPCTSTR szFileName,//填写下载完成到本地,保存的文件名
DWORD dwReserved,//保留参数,必须为0
LPBINDSTATUSCALLBACK lpfnCB //接受下载进度的回调函数,不需要,直接填0
);
返回值为S_OK则成功,否则下载失败
函数功能:将zURL参数地址下载保存为本地szFileName参数文件
上面这个函数为windows的函数,主要作用就是下载东西的,非常好用。
但其参数是相当繁琐的,而且其数据类型我们居然看都没看到过,难不成我们前面学的C++都白学了吗?
不用慌,这只是障眼法罢了!先在VS中将该函数写下来再说!
#include<Windows.h>
#pragma comment(lib,"Urlmon.lib")
int main() {
URLDownloadToFileA();
}
这里教给大家一个学习win API的方法,所谓API,即 应用程序接口(Application Programming Interface) 英文首字母的缩写。
win API就是windows的接口,所谓接口,说白了就是一个个函数,比如上面这个函数。
前面提到过,如何快速查看win API的帮助文档,还记得吗?
非常简单,就是在VS中,鼠标点一下这个函数,然后按F1即可(可能需要先点击功能键Fn),就会跳转到该函数帮助文章。
当然你直接在浏览器中搜这个函数的名字也是可以的,官方文档链接为:URLDownloadToFile。
官方文档永远是你能够最全面了解该函数作用的地方,但很无奈的是,其内全是英文,而且还有很多专有名词,很难看懂怎么办?
最有效的办法就是去浏览器搜索该函数名称,会有很多中文解释,然后对照着英文看!
直接翻译当然也行,但不是很建议,因为很多地方翻译出来的效果并不是很理想,容易让人误解,看的云里雾里的。
而我们如何知道这个函数所在的头文件和需要哪些库呢?同样也是看文档,页面的后面:

可以看到,这个函数需要头文件Urlmon.h,静态库文件Urlmon.cpp,动态库文件Urlmon.dll。
到这里你可能有几点疑问:
- 明明需要的是
Urlmon.h头文件,为什么我前面写的是windows.h头文件? - 静态库前面提到过,动态库是什么东西?咋没用到?
首先,windows.h头文件几乎包含了所有的win api,Urlmon.h也在其中,为了简化记忆,我们一般想要用win api了,就直接添加windows.h就可以了。
因为这样VS就有函数名提示了,写好函数后按F1,来到帮助文档,看看是否还需要其它条件,所以说这个头文件名字是一定要记住的!
然后就是动态库的问题,并不是我们没有用到,只是我们没有看到而已,暂时不用管,后面章节会教大家如何写自己的动态库与静态库!
一般来说,win api的动态库我们都不用管,因为这些动态库,随着windows系统的安装,就都被放在了系统文件夹中。
然后回到这个函数,它有很多奇怪的参数类型,但不用慌,我们直接看这个函数的定义,方法是什么还记得吗?右键这个函数,然后点击速览定义即可:

可以看到,这里有很多类似的函数,但现在我们关注这个的函数可以看到它有5个参数。
第一个参数与第五个参数看上去很长很复杂,先看一眼文档:
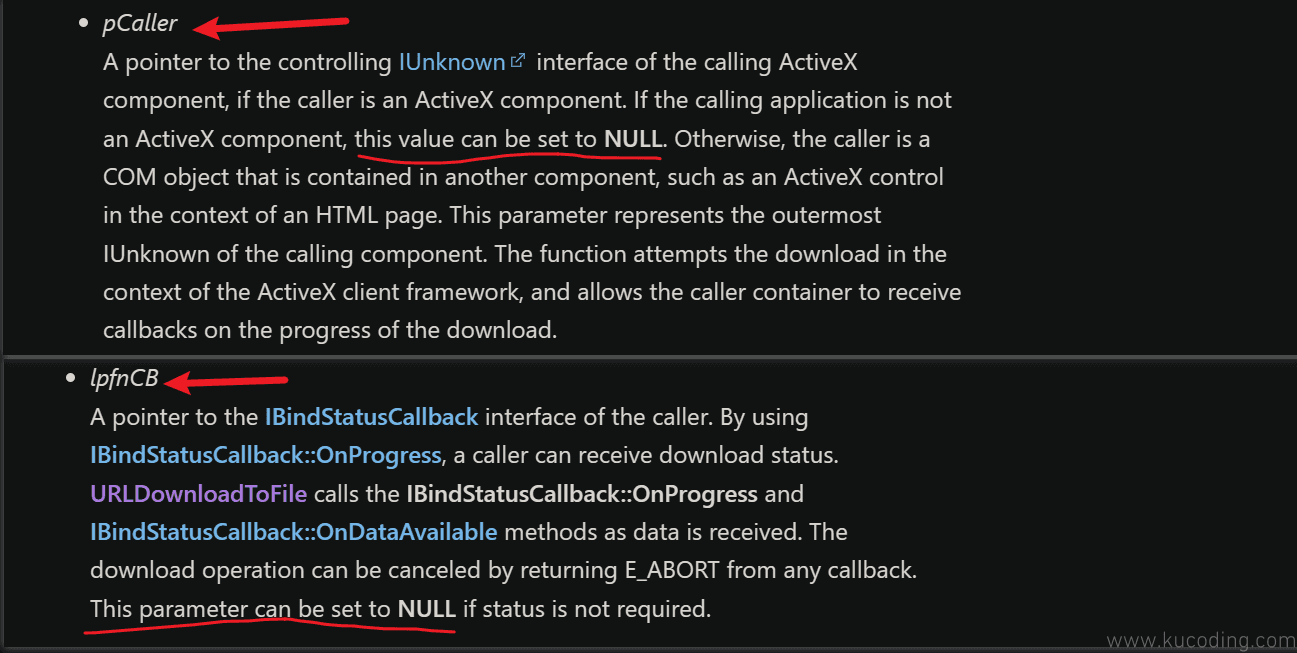
这是用于查看下载进度的参数,但我们不需要,可以直接填NULL,那就不管了。
然后看到第四个参数,必须填0,那又不用管了。

现在就只剩下第二个参数与第三个参数了,稍微翻译一下就是,需要我们填要下载的链接,以及下载后保存的文件,这是必须要填的。
可以看到第二第三两个参数的数据类型都是:LPCSTR。
那我们再来看看这个数据类型到底是何方神圣,怎么以前我们没见过?
还是老方法,直接点击它,然后鼠标右键菜单、点击速览定义:
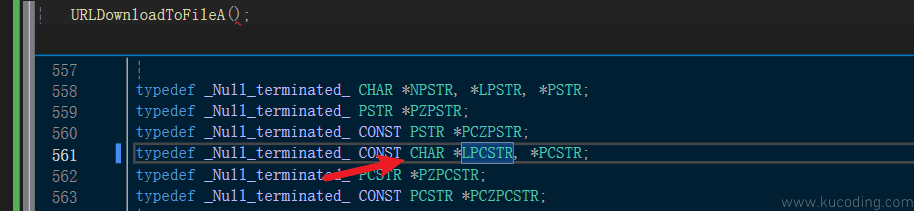
可以看到,这里使用了typedef,其作用就是将CHAR*定义了两个新名称: LPCSTR,PCSTR
注意这是定义指针名称的方式,如果定义多个名称,*号就要写多次,中间用逗号隔开。
还有前面这种一大串东西,紫色的,一般都是空宏,也就是有没有它效果都一样,目的是给我们程序员看的,比如上面这段宏的意思就是,以0结尾的常量字符串。
还有前面的函数参数前也有,什么带有in、out的,也都是空宏,告诉我们这个参数是用来输入还是输出的!
但问题来了,CHAR我也不认识啊!那就继续右键它,速览定义:
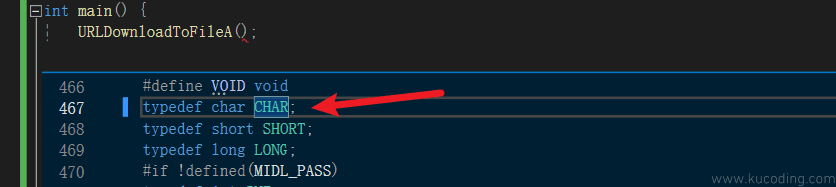
现在是不是认识了!其实就是一个char而已,一串定义下来,其实就是个char* 的数据类型,意思就是这个参数接收一个字符串。
以后你在vs中遇到任何没看到过的数据类型、函数,都可以这样做。
现在,就让我们来进行第一步,下载网页源码:
#include<Windows.h>
#pragma comment(lib,"Urlmon.lib")
int main() {
URLDownloadToFileA(NULL, "http://www.netbian.com/", "1.txt", 0, NULL);
}
其中http://www.netbian.com/为网页地址,常被称为URL,在浏览器上方可以看到:
直接复制粘贴,就会自动补全前面的http://,代表该链接用的HTTP协议,这里就不再深入了,了解一下即可,相应的其实还有https://,代表https协议。
然后运行一下代码试一试!因为我们没有进行任何输出,所以什么都看不到。
来到项目文件夹,看看是不是下载成功了!

可以看到,我们成功将网页的源码下载下来了。
4.2 提取图片URL
这一步要稍微繁琐一点,因为我们需要的是提取这么长的文本中一小段字符串,如果是自己用char* 或者string来操作,虽然也可以,但过于复杂,所以这里介绍另外一种方法,那就是正则表达式
正则表达式是个什么东西呢?它其实并不复杂,就是一种文本模式,其主要用途就是:提取、匹配、替换字符串。
更多详细的内容可以参考本站文章:regex库使用。
它的应用范围极其广泛,几乎只要你日后写代码,就一定会用到它,它并不局限于某一种语言,所有语言都有它的存在。
所以不会的一定要先去学习!这里只会简单的介绍一下它,不会过多的赘述。
首先正则表达式库在头文件regex中:
#include<regex>
一般来说,我们都是使用标准库string来表示字符串,所以我们一般用到下面这几个函数与类:
using std::regex; //保存正则表达式
using std::smatch; //保存匹配到的结果
using std::regex_search; //用于找子字符串
using std::regex_match; //用于匹配整个字符串
using std::regex_replace; //用于替换子字符串
上方最后面三个是函数,通用于char *与string这两种字符串表示方法。
第一个为保存我们写的正则表达式,也是通用的,但第二个就是专用于string的,如果要用于char*,就应该使用cmatch。