1.array
有了前面一章的基础,我们就可以正式来学习使用各个容器了,首先是序列式容器。
注意这些容器会用到最基础的数据结构,如果你对此还不慎了解,那么可以先看看这篇文章:数据结构与算法。
这个容器可能我们平时用的较少,它是一种定长的容器,看名字就知道,基本和我们平时使用的数组没有什么区别。
声明的方式为:
#include<array>
#include<iostream>
using namespace std;
int main() {
array<int, 100> arr;
}
其模板参数, 第一个为要存储的类型,第二个为大小。
其特点是一旦声明了,这个数组的大小就不可更改了。
你可以像普通数组那样赋值与获取值:
array<int, 100> arr;
arr[0] = 1;
cout << arr[0]<<endl;
但通过下标获取值容易出现访问越界,比如这里为100个元素,范围为0-99,你却访问下标为100的元素,就超界了,有时就会出现获取的值不对,或者程序直接崩溃。
为了解决这个问题,我们可以通过它提供的函数来获取值:
array<int, 100> arr;
try
{
cout<<arr.at(100);
}
catch (const std::exception& e)
{
cout << e.what();
}
然后我们在最外层套一个异常处理,如果越界了,它就会抛出异常,然后我们这个try catch块就会捕获到。
不熟悉异常用法的可以参考文章:异常处理。
我们还可以使用get函数,在编译期间获取这个值:
array<int, 100> arr;
cout << get<100>(arr);
如果越界, 就会直接编译失败:
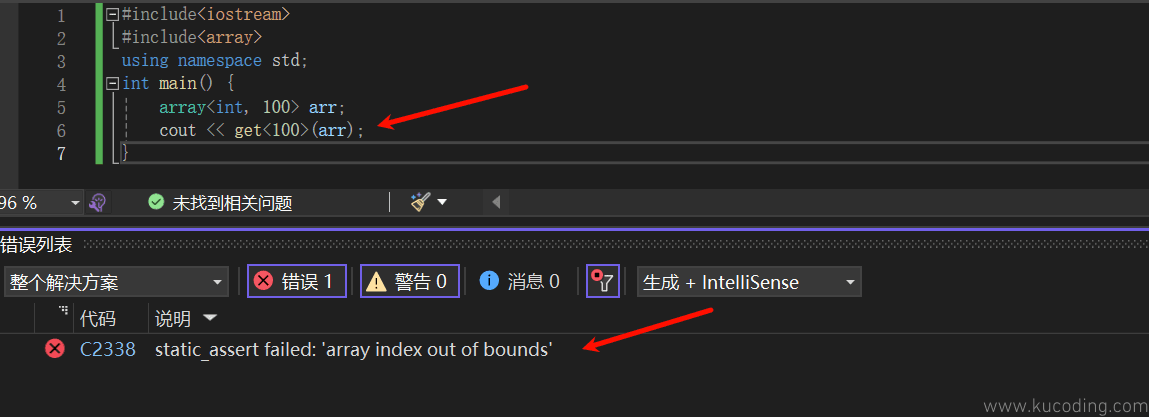
注意这个get函数, 是std里面的,它的模板参数就是你想要获取元素的下标值,而参数就是哪一个对象。
同时要注意,由于它是编译期间完成取值,所以其模板参数不能为变量,只能为常量。
你也可以获取这个数组指针:
array<int, 100> arr;
arr[0] = 1;
int *num=arr.data(); //获取数组指针
cout << num[0]<<endl; //通过指针来获取值
也可以为它所有的元素都填充数据,并遍历输出:
array<int, 10> arr;
arr.fill(100);
for (auto i = arr.begin(); i != arr.end(); i++)
{
cout << *i << endl;
}
当然你也可以使用反向迭代器来逆向输出:
array<int, 10> arr;
for (int i = 0; i < arr.size(); i++)
{
arr[i] = i;
}
for (auto i = arr.rbegin(); i < arr.rend(); i++)
{
cout << *i << endl;
}
begin函数前面添加一个r,即反向的意思,rbegin函数返回指向最后一个元素的迭代器,而rend则返回第一个元素之前一个位置的迭代器。
注意这里同样使用的是++,这就是反向迭代器。
还有更加简洁的遍历方式:
for (auto& i : arr)
{
cout << i << endl;
}
所有支持迭代器的容器,均支持这种遍历方式
auto为自动推断arr中元素的数据类型,这里可以写为int,&代表引用,如果不添加,那么就是拷贝过来赋值给i变量,对于对象元素来说会造成更大的消耗。
除了上面的普遍用法外,它对字符数组的支持也非常好,我们完全可以用它来代替普通的char[]字符数组:
array<char, 100> arr;
strcpy_s(arr.data(),100,"https;//www.kucoding.com");
cout << arr.data() << endl;
2.vector
这个容器相信大家应该是最熟悉的,因为它长度可变,几乎可无限追加数据,并且可以像普通数组那样访问,使用起来非常方便,使用频率也非常高。
但使用它也需要注意效率影响,它底层同样是一个有限的连续内存块,它和string一样, 一旦这个内存块不够了,那么它就会重新开辟一块更大的内存,并将原有的数据拷贝到新内存块中。
理解连续内存块这个概念很重要, 因为这意味着string不能做的事,就可以用vector<char>来做。
比如string默认是以\0结尾的,这在处理网络数据的时候非常不便利,你不能保证别人发来的数据字节里面没有\0,比如给你发个图片字节数据,里面肯定或多或少存在\0字节。
但用vector就完全没有这个问题,因为它可以将\0作为一般字符处理,最后可以通过它的data函数来获取这个内存块地址,非常方便。
初始化的方式有很多:
#include<vector>
#include<iostream>