1 前言
一直以来大模型本地部署都是一件非常繁琐的事情,但ollama的出现改变了这一切。
ollama的作用在于,它封装了所有模型底层细节,提供了非常简单的命令、以及可以在几乎任何电脑上都能运行模型的能力,即使你没有显卡,也能让模型跑在你的CPU上,极大的提高了大模型的普及程度。
如此一来,即使是对大模型一无所知的开发者,也能快速在本地搭建大模型、并用其完成一些简单的任务,比如图片识别、分类之类的。
2 ollama安装与基本使用
ollama官网为:Ollama,直接在主页下载该程序安装即可,成功安装后,ollama会提供了一个名为ollama的命令行工具,用来管理所有大模型。
并且在托盘上也能看到ollama的图标:

ollama的使用方式极其简单,我们只需要去找其官网找到我们想使用的模型:
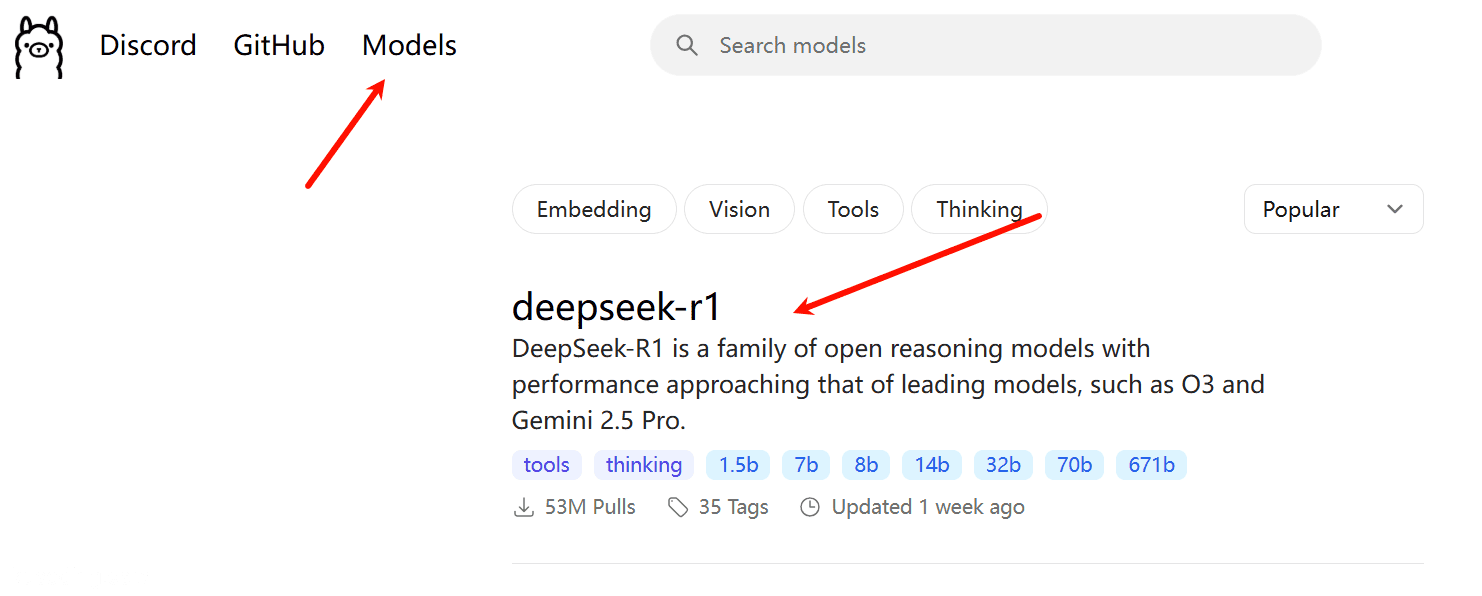
比如位居首位的deepseek模型就是我们中国公司深度求索开源出来的一个非常受欢迎的开源大模型。
点进去就能看到拉取模型的命令:
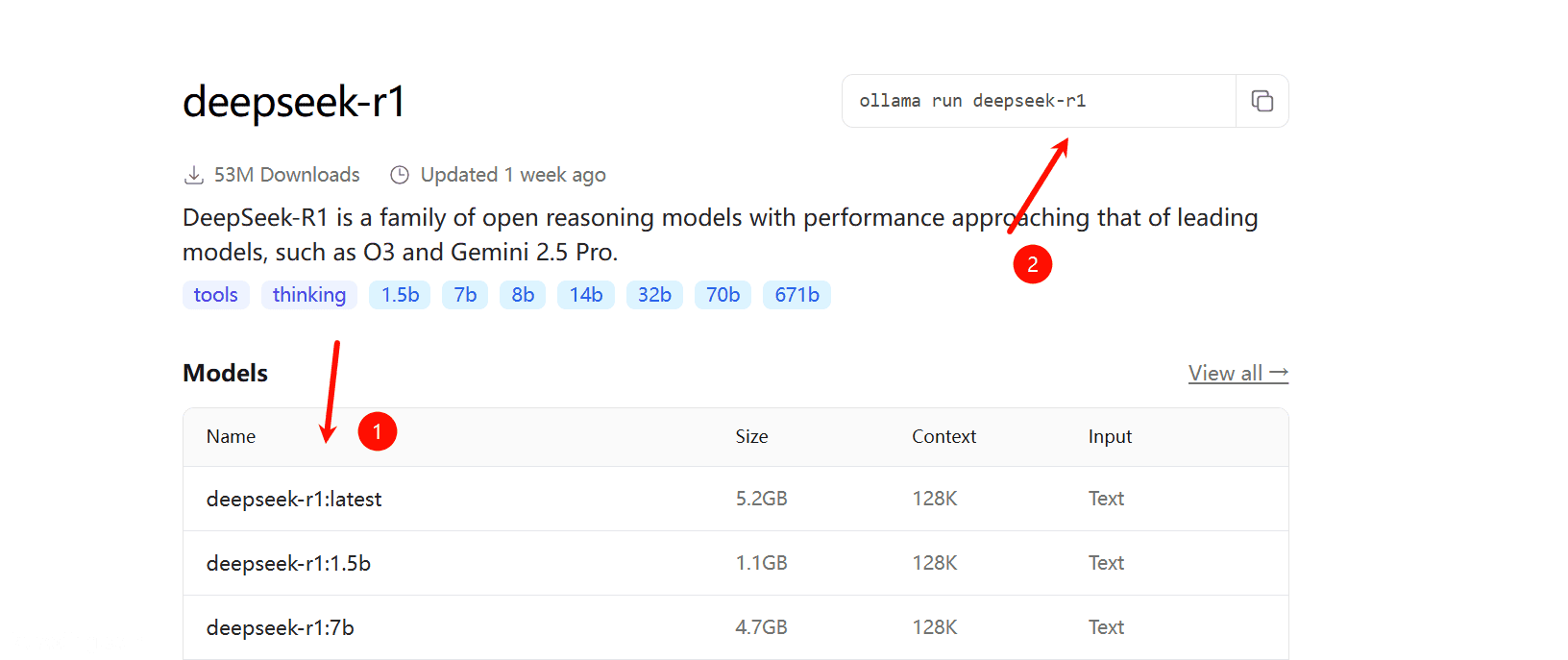
其左边是大模型的名称与对应的参数,参数越大一般代表其效果会越好,但其所需要的硬件条件也会越高。
而右边便是拉取该模型的命令。
一般16G、无独显的计算机,大概就只能跑8b左右的模型,一旦选择过大的模型,会导致运行极其卡顿,甚至完全没法运行。
我目前的电脑是32G内存、外接一张4060 TI独显,可以比较顺畅的跑28b规模的模型,但大多数时候,为了能让大模型响应迅速,我跑的也多是10-20b之间的模型。
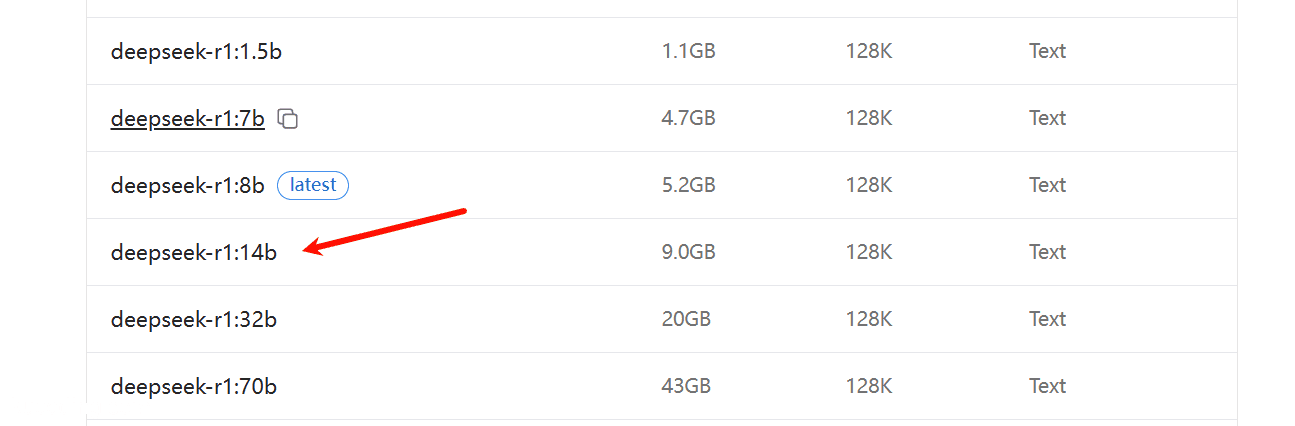
比如deepseek-r1的14b版本:
注意这里的命令:
ollama run ...
代表是运行该模型,如果不存在则会自动拉取该模型,如果想要只拉取不运行,则使用ollama pull ... 命令。
比如我想要运行这个14b的模型,就可以运行命令:
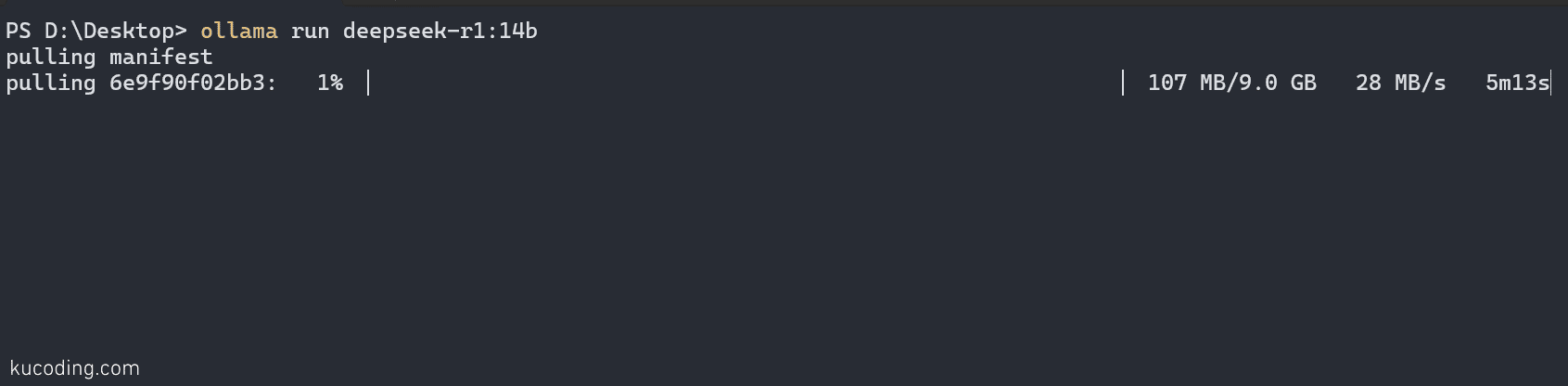
等待其下载完成后、运行起来,我们就能直接和它对话了。
注意它默认是安装到C盘的,老版本需要修改环境变量更改它的安装目录,新版本可以直接在设置里面修改:

而且可能是ollama服务器的限制,每次拉到最后时,下载速度就会变的非常慢,此时可以直接按Ctrl+C终止下载,然后重新运行命令、它会续下载,并且下载速度重新恢复到前面的速度。
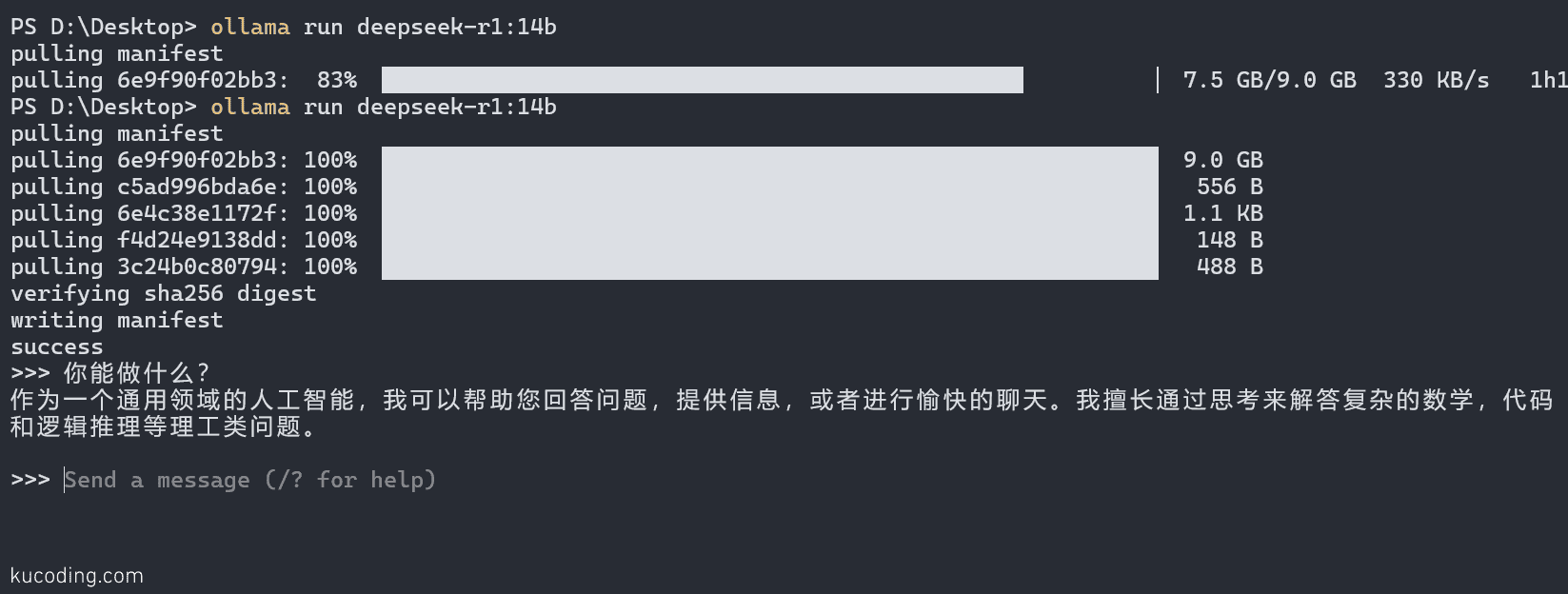
如果想要退出对话,可以使用快捷键:Ctrl+D。
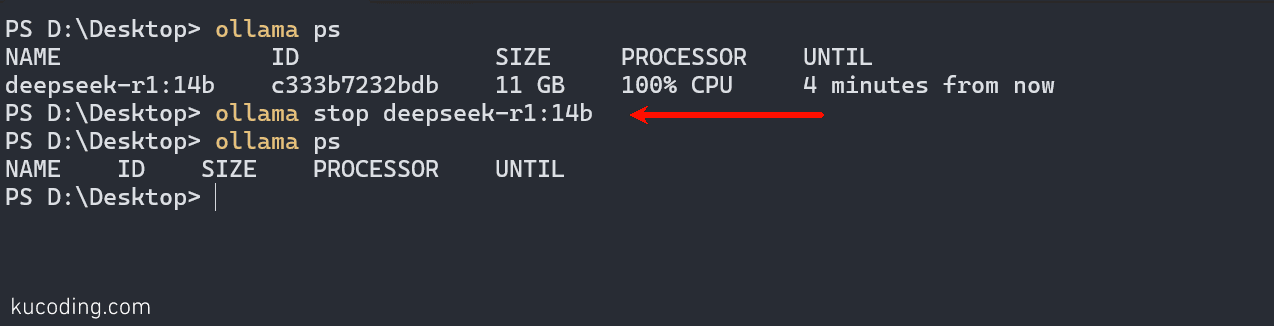
注意退出对话并不代表模型停止运行了,你可以通过命令ollama ps查看当前运行的模型:

然后使用 ollama stop ...去停止该模型运行:
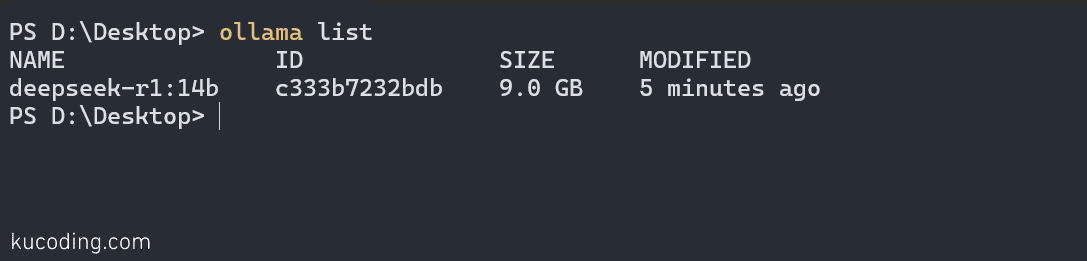
如果你拉取了多个模型,可以使用 ollama list命令查看当前拉取了哪些模型:
如果不想使用哪个模型了,就可以直接使用命令删除:
ollama rm ...
这会彻底删除模型释放本地磁盘空间。
3 图像识别实践
一个比较好的开源图片识别模型是llava,实测效果很不错:
ollama pull llava:7b
ollama pull llava:13b
ollama pull llava:34b
它提供了多个参数的模型,可以按需拉取使用,就我来说,为了提高识别效率,会使用13b的,但如果你想要提高图像识别精准度,那么可以选择34b,或者为了有更快的速度,可以选择7b。
有了模型之后,我们就可以编写python代码与ollama模型对话了。
ollama程序只要启动,就会默认暴露一个本地web服务,可以让我们用其它程序直接调用大模型进行对话,其默认端口为:11434
所以许多语言都有相应的ollama库,用于直接调用这个web服务,实现与大模型对话。
由于python代码编写简单,所以这里就用python了:
pip install ollama
使用起来也非常简单:
import ollama
resp = ollama.chat(model="llava:13b", messages=messages)
直接调用ollama上的chat函数即可,它的model参数用于指定我们想要和哪个模型对话,而messages则是我们想要向模型发送的消息,是一个对象数组:
messages = [
{
"role": "user",
"content": "发送给大模型的话",
"images": [
r"D:\pictures\b1.jpg",
r"D:\pictures\b2.jpg",
r"D:\pictures\b3.jpg",
r"D:\pictures\b4.jpg",
r"D:\pictures\b5.jpg",
],
}
]
其中每个元素都是一个对象,这个对象中用的最多的就上面三个属性:
- role:角色,一般为用户,也就是
user,我们发送的消息,但你也可以填写system,代表系统提示词,还可以填写assistant,代表是模型本身的输出内容,如果你想要持续对话、拥有记忆,那么你就需要将其上次传回的内容通过这个角色发送回去。 - content:该角色说的内容
- images:对于图片识别模型来说,需要通过这个参数传入我们想要让大模型识别的本地图片路径,如果有多张图片,那么就挨个写入其中即可。
最后,模型会根据你发的消息响应相应的内容,可以通过下面的语句获取它的响应消息:
content_detail = resp["message"]["content"]
而我们要做的关键点便是写提示词,让大模型可以高效的提供我们所想要的内容。
经过我数天的反复测试,对于本地大模型来说,一个比较好的方式是通过chatgpt等更加强大的大模型帮助我们生成提示词,然后将该提示词喂给本地大模型使用。
比如我有近两万张图片,里面大量图片存在日历元素,我希望能够将这些有日历水印的图片筛选出来,我发给chatgpt的内容如下:
生成一段英文prompt,用于大模型图片识别,目的:识别图片中出现的任何日历元素,如果你确定该图片100%包含日历则返回true,否则返回false,不要返回多余的内容
然后其为我生成的prompt如下:
Please carefully analyze the input image and determine if it contains calendar elements. Calendar elements include information such as dates, months, years, or weekdays displayed in the image. Return true only if you are 100% certain that calendar elements are present; otherwise, return false. Ensure that the result is strictly limited to true or false with no additional information.
此后的事情就比较简单了,我需要循环不断的将这个提示词与一张图片喂给大模型,如果其返回true,我就将其移动到另一个目录,等其处理完毕后我只需要最后再人工看看效果即可。
经过实测,这段提示词结合llava:13b模型可以达到一个非常好的日历识别效果,唯一遗憾的这个模型还是比较弱,依旧有不少图片有日历、但无法被它识别。
这种情况下你可以适当调低比例,比如上面的提示词中我要求的是100%确定,你可以调成80%之类的。
除了上面这种筛选指定元素图片的方法,另一种是直接结合两种大模型的优势,直接生成一张图片的所有包含属性、甚至所属类型。
方法也很简单,让识别图片的大模型尽可能详细的描述图片中的所有元素、风格,然后将其返回的内容再喂给另一个对话大模型,让其将文本总结为关键字。
最后,我们就可以通过程序直接识别关键字对图片进行分类。