1 外挂介绍
写游戏外挂是一个高风险高收益的行业,本文以及本系列文章只做学习探讨,并不鼓励大家从事外挂行业。
外挂本质上其实就是一个简单的程序,只不过它与一般的程序又有些不同。一般的程序只控制修改自己的数据,而外挂却是去控制修改其它程序的数据。
随便拿一个游戏作为例子,一般一个角色会有一些属性,比如血量、蓝条等等,这些属性数值实际上就是保存在游戏这个程序中的变量而已,更底层一些就是这些数据是保存在这个程序的内存地址空间中。
而角色的动作,比如砍一个怪让其掉血,从代码层面上来说就是调用了一个函数,这个函数用怪的血量减去角色的攻击力,得到怪的剩余血量。
至于你所看到的游戏各种炫酷画面,都是在这些代码基础之上添加的动画。
一些古老的游戏,比如10年左右的一些手机网页游戏,很多都是纯文字的网页游戏,非常纯粹,没有任何动画,就是一个角色拥有各种数值属性、闯关后遇到了什么怪、打了多少下、掉了多少血、获得了什么物品。
游戏的本质其实就是这些,只是现在的游戏将动画提升到了非常高的优先级别,让你不太容易一眼看出游戏的底层逻辑。
其实无论是破解软件、还是写游戏外挂,最好的方式其实就是你先会开发。只有你真的写过软件,了解过软件的底层运行原理,你才知道应该怎么用最好的方式去破解它,游戏同理。
2 外挂类型
虽然我们常常能看到各种各样的外挂,但只要稍微分析一下就会发现,外挂的功能就只有两种类型:
- 修改数值
- 修改行为
数值是比较简单的,就是改角色数值嘛,比如角色金币只有100,直接给它改到9999999。
其实现逻辑其实并不复杂,甚至可以说非常的通用。
对于只是想要简单的、自己使用的游戏外挂,就没必要去写程序,直接用CE这类工具查找数值在内存中的位置,然后修改数值即可。
但如果你想要将这个功能写成一个外挂发给别人使用,那么你还需要根据找到的地址,继续分析基地址,最后写程序动态获取数值的地址,修改数值。
而行为则比较复杂了,因为其本质上是去修改相应的函数,你得至少会一些汇编的基础,不用会写,只要会看就够了。
比如无敌外挂,本质上就是去找到角色扣血的函数,然后修改这个函数的一些值,比如跳过扣血、让扣血的值始终等于0。
又比如穿墙外挂,本质上就是去找角色与物体的碰撞检测函数,只要找到了这个函数的位置,那么只需要修改其检测的结果,就能让角色穿墙。
3 前置知识
为了更好的理解后文制作外挂的步骤,本节大致过一遍需要的理论知识。
首先是进程隔离与地址空间。
每个应用程序至少包含一个进程,进程之间的数据是互相隔离的、正常情况下无法相互访问,而隔离的方式就是地址空间,每个进程都有自己的地址空间,进程之间无法直接访问互相的地址空间中的数据。
不理解的可以参考前文基础:Windows注入技术
而我们的目标便是突破进程地址空间的限制,让我们的程序能够访问目标进程的地址空间,winapi中提供了相应的函数可以做到这一点。
这是比较高级的用法,更简单的方式其实是将我们的代码写进dll,然后直接将我们的dll注入目标游戏进程中,此时就在同一个地址空间中可以直接修改了,为了简化流程,本文将使用更加通用的dll注入技术编写外挂。
上面的基础可以让我们实现修改游戏进程中的数据,但我们如何知道修改目标中哪一块的数据呢?
这就需要一些工具的帮助了,比较常用的就是CE:Cheat Engine安装。
它的作用就是搜索指定进程中的某个数据,通过不断的搜索比较来确定目标数据的地址,然后进一步通过它分析数据的基地址,有了基地址我们就能一步一步转换、动态拿到游戏的数据地址,通过程序进行修改,也就是基本的数值外挂。
注意这里的基地址,实际上指的就是main函数中的变量地址:
struct Role{
int blood;
}
int main(){
Role *a=new Role();
}
假设上面是一个游戏中的数据,那么我们用CE搜索角色血量拿到的地址实际是变量blood的地址。
注意,现代游戏基本都是使用C++或C#开发的,乃至一些其它语言开发的游戏,对于一个角色的数值结构基本都是使用类、结构体这样的结构进行组织的,因此这里以结构体进行介绍,对于C++语言开发的游戏来说,更可能使用的是类。
但你会发现,Role这个结构体是通过new关键字动态分配的,也就是说,这个地址每次启动后都会变。
那么什么不会变呢?自然就是这里的变量a。
a变量始终存在于main函数内部的第一个变量栈空间位置,而main函数在内存中的加载位置又是可以通过winapi拿到的。
winapi实际上拿到的地址是更底层的入口,但整体偏移量是固定的。
所以我们只要能拿到a变量的地址相对于入口地址的偏移量,那么无论程序启动多少次、只要不重新编译,那么我们都能直接拿到a变量的地址,只要能拿到a变量的地址,那么自然就能一步一步跟踪偏移量拿到里面的数值了。
这里只是简单的一级指针,实际的游戏中会有很多层指针,需要耐心分析。
多级指针在代码中的展现形式类似于:关卡类 包含 角色类字段,角色类 包含 基础属性类字段 基础属性类 包含 血条蓝条等基本字段。
这种在代码中不断进行嵌套的结构,在底层的展现形式就是多级指针。
对于数值类型的外挂,大多数时候只使用CE就足够了。
如果还想要做行为外挂,那么可能还需要用到另一个逆向分析工具:x64dbg
它的作用就是分析游戏代码执行逻辑的,但需要你能读懂一些基本的汇编指令、并能够进行一些基本的修改汇编指令行为。
因此从整体上来看,编写代码并不是非常困难,难的是分析数据。
4 CE查找基质
想要实现数值外挂,第一步就是寻找数值在内存中的地址。
这里使用入门级游戏植物大战僵尸为例,为其编写简单的外挂程序,游戏下载地址为:PlantsVsZombies.zip
由于这个游戏是32位的,所以这里我们启用32位的CE:

如果是64位的游戏,那么就使用64位的CE即可,方法都是一样的。
然后运行植物大战僵尸,启动CE,在CE中找到植物大战僵尸僵尸的进程、并附加它:

紧接着我们就可以开启关卡,这个游戏中最简单的数值自然就是阳光了:

比如我们可以看到这里的数值是50,那么就回到CE中搜索50:
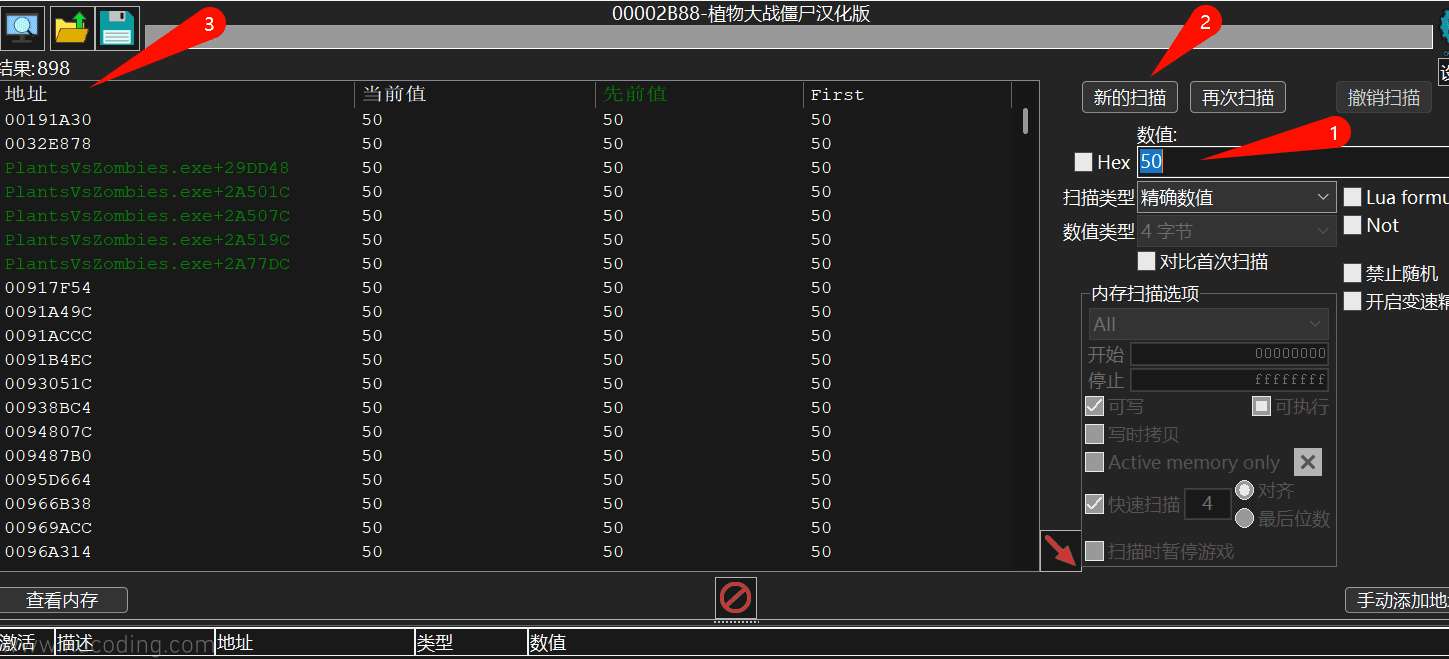
但是可以看到,直接搜索50这个数值会发现并不止一个地址,有非常多的地址上的值都是50。
为了跟进一步缩小范围,我们就可以回到游戏中,增加或减少阳光的数量,然后选择“再次扫描”:
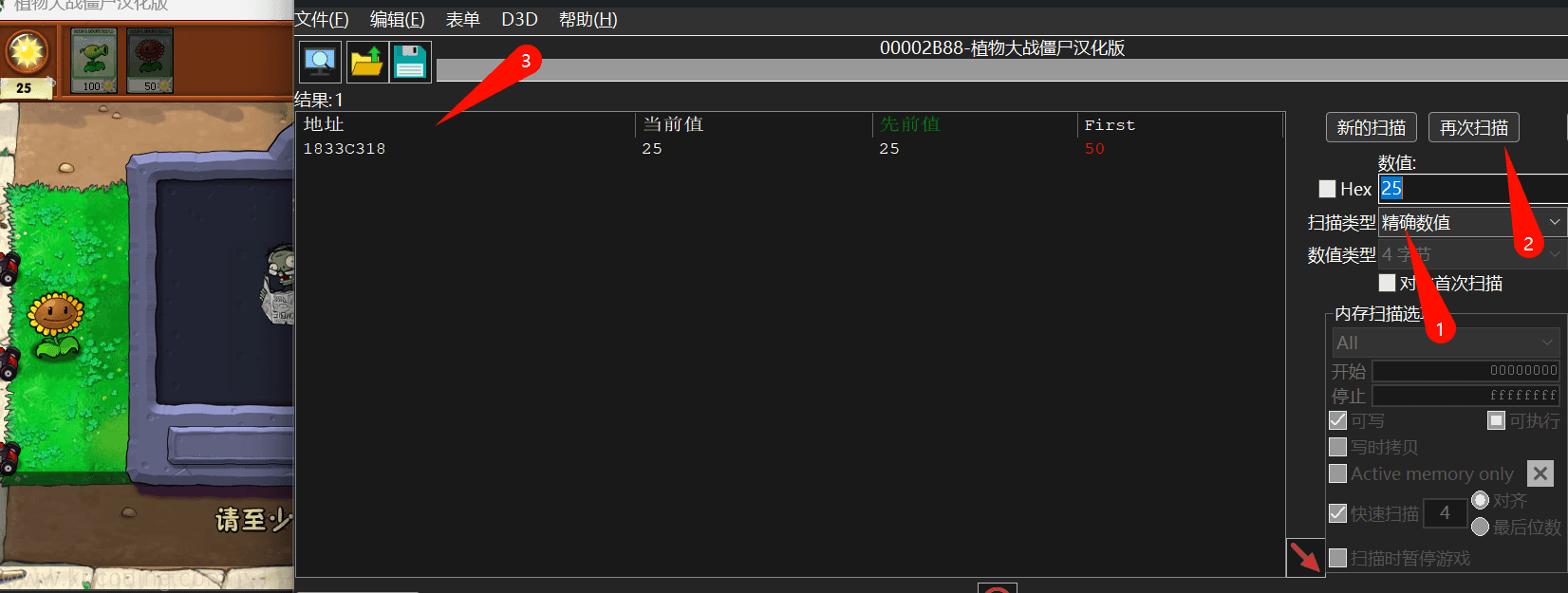
这个游戏就比较简单,一下就让我们找到了阳光数值所在的地址。
但要注意,这里的地址并不是绿色的,在CE里面只要不是绿色的地址,就说明这不是基地址,你也可以直接理解为这个数值变量并没有直接写在main函数里面。
双击这个地址,这条数据就会被自动添加到下面的小框中,然后再双击一下,我们就可以修改这个地址上的数值:

可以看到,游戏中的阳光数值也随之改变了:

这说明我们已经正确找到了阳光的地址,下一步我们就需要来寻找它的基地址。
4.1 逐步分析
寻找基地址的方式有许多,这里首先介绍一下如何自己一步一步分析基质。
分析的方式并不难,首先来到上面找到的阳光地址位置,右键它,点击“找出是什么改写了这个地址”:
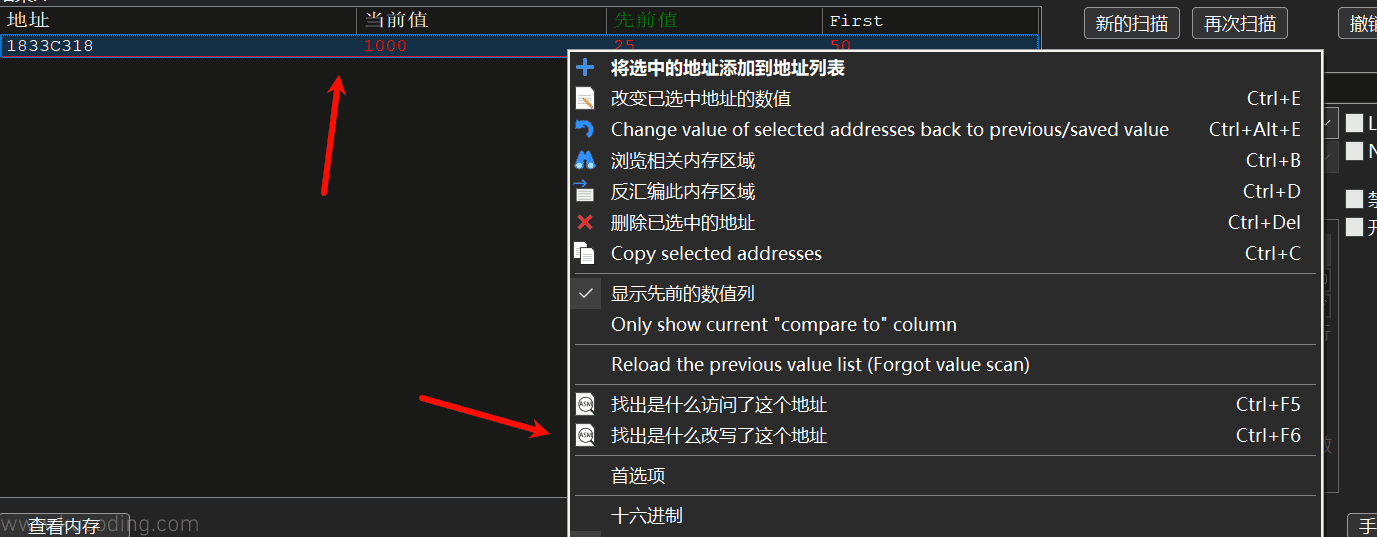
然后回到游戏中,让阳光数量改变一下,比如捡一下阳光,然后回到CE:
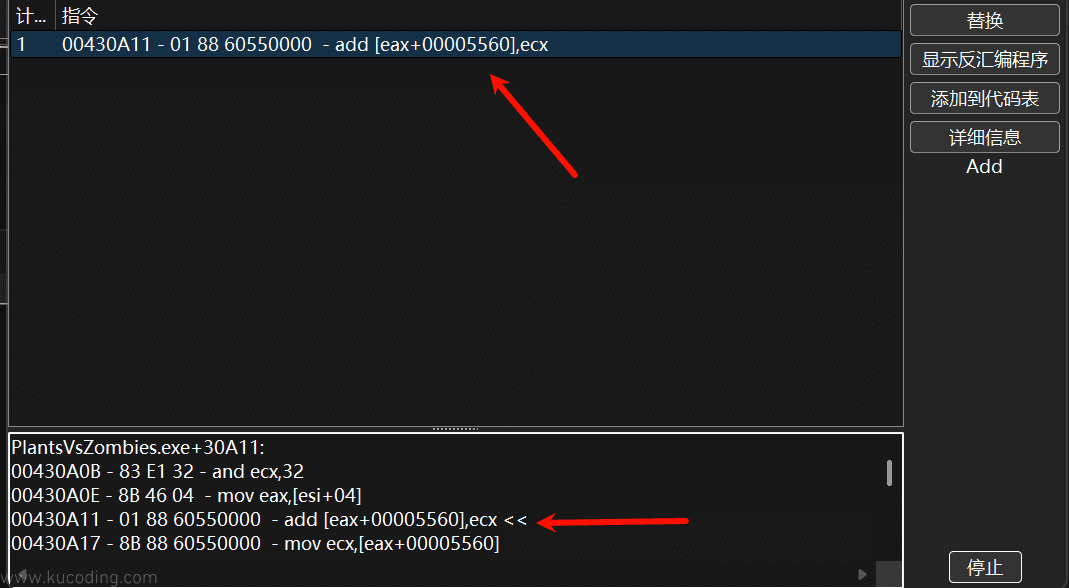
此时我们就能非常容易的找到捡阳光后添加阳光时所触发的代码位置。
这条汇编指令的含义是在eax+5560地址的数值基础上加上ecx数量的数值,显然这里的eax+5560就等于阳光数值的地址1833C318,所以eax寄存器里面存放的就是指针,至于ecx存放的自然就是游戏中捡到的阳光数值了。
此时双击一下上面这个地址,CE就能帮助我们查看eax寄存器此时的值,也就是指针的值:
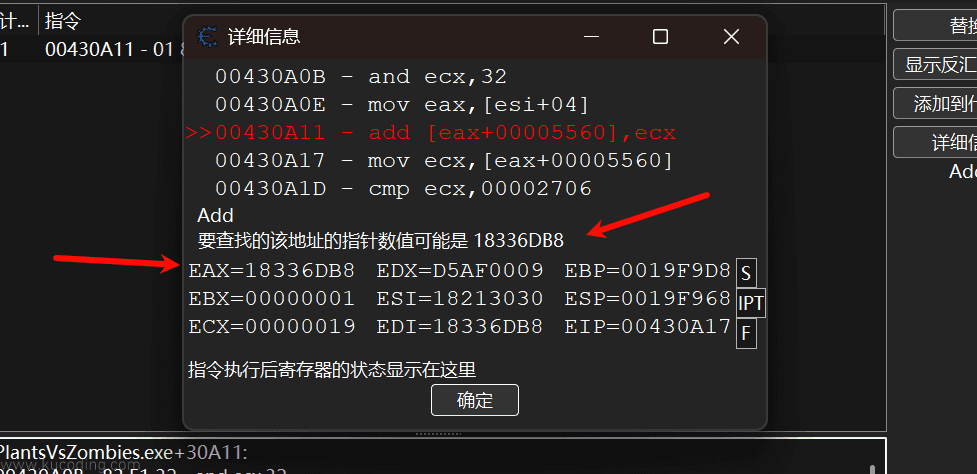
可以看到,CE怕我们看不懂汇编,甚至都直接用文字写明了。
所以此时我们第一步就分析出了这样的信息:
18336DB8+5560=存放阳光数值的地址
然后下一步便是查看这个指针的值是不是基地址,方式就是直接在CE中搜索这个地址:

但可以看到,依旧有很多地方存放的值都是这个,并且没有一个绿色的地址。
此时第一步要做的一般是回到游戏中随便点两下,然后回到CE中直接点击“再次扫描”,把这期间变过数值的地址都过滤掉。
但经过我尝试之后,发现这样并不能过滤很多,所以下一步就是挨个尝试,这同样也是有规律的,不要随便见到一个地址就跟进去追、浪费时间。
比如这里我们找到的是存放阳光字段的对象,这与关卡有关,所以可以合理推测我们上面找到的这个指针实际上就是一个关卡对象的首地址,在我们没有退出当前关卡的情况下,理论上来说这个关卡的信息就不应该被释放掉、也就是不应该被修改。
所以如果看到一个地址上的数值一直频繁发生变化后又很快变回去了,那么就可以直接忽略它,比如这里得到的第一个地址就是不断的发生变化、然后又很快的恢复。