1.前言
相比于需要观察汇编、字节码这种非常底层的逆向工程,js逆向相对来就要简单许多,因为浏览器所运行的绝大部分代码都是明确的字符代码,即使是做了混淆处理,依旧可以从中较为容易的分析出内容。
而现代绝大部分资源基本都是放在了网站上,只因起开发起来过于简单,因此成为了大部分站长的首选。
所以学习js逆向的应用空间非常广泛,比如常见的爬虫,第一步往往就是通过js逆向去分析目标网站的信息数据,又比如攻击目标网站,第一步一般也是js逆向分析网站漏洞。
而本章的目的就是带大家实战js逆向,同时编写python代码实现对一个网站的资源爬取。
本章所涉及的所有代码均仅供教学使用,切勿应用于非法行为。
2.js介绍
无论现代前端框架迭代的有多么快,应用了多少现代先进理念与技术,想要最终在浏览器中跑起来,都必须要将其编译为html、js、css这三类代码文件。
只不过由于经过了编译,所以此时原代码作者所编写的源码我们是无法在浏览器中看出来的。
我们在浏览器中所能看到的代码,往往都是经过编译器编译、混淆、优化之后的、与原代码功能等价的代码,虽然它们依旧还是js代码,但人为辨识度却要低得多。
3.实战分析
由于本文只做技术分析,为避免被搜索引擎搜录而导致不必要的争端,目标网站地址放在了文末。
1.列表分析
分析网站的第一步,就是打开浏览器的开发者窗口,一般是按F12开启,并点击网络选项卡。
然后第一步是分析它是如何取图片的,所以我们需要先点击一下网站下方的分页,比如第二页:

此时可以非常轻松的看到有一个fetch类型的请求,并且其URL为getWallpaperList,很明显这个url的意思就是获取壁纸列表。
fetch类型的请求,就是使用js代码发送的请求,一般用于网站动态从服务器中获取数据,比如这里的图片就是通过该请求动态去服务器拿取的。
至于其它png类型的请求,很明显是在获取对应的图片数据,但这个网页只有小图,并不是我们的目标,所以忽略它们。
然后单击这个请求,就可以看到其内的详细信息:

首先看负载,也就是该请求向服务器发送的数据,可以看到它是一个键值对,data以及其所对应的值,但其值一看就是被处理过的,是一串纯字符串,没有任何有用信息。
然后我们再来看一看它的响应,也就是服务器所返回的数据:

可以看到,服务器的响应比较规范,是一个json对象,但其实际的data数据明显也是被处理过的。
遇到这种数据是一串纯字符串,并且其末尾时常还带上 = 符号的,我们就可以初步猜测其使用了base64编码。
base64是一个非常通用的编码形式,因为它可以将任意数据转换为一串字符串,甚至包裹图片、视频都可以,这样方便网页数据传输,以此避免某些情况下的符号不兼容问题。
比如url本身就已经使用了符号 ? 用于表示查询参数,如果你get请求的参数数据中也带有问号就会出问题,而base64就可以将这些数据全部转换为由字母数字以及少量的符号组成字符串,从而解决这些问题。
根据经验来说,只要一串字符串的结尾带有等号,就可以认定其使用了base64编码。
所以第一步尝试就是直接将负载的字符串复制出来,然后随便找一个base64在线编码解码的网站尝试对其解密:

但很遗憾,它这里并不是单纯使用了base64编码,因为直接解码出来是乱码。
因此可以推测其除了使用base64编码外,一定还使用了其它加密方式。
此时我们就需要稍微深入一下去看其源码进行逆向了,首先来到源代码,全局搜索这个url名:

可以看到,使用到的地方并不多,只有4个,然后挨个查看即可:

这四个中,后两个可以直接排除,因为点进去后会发现它们里面根本没有这个url数据,并且其所处的文件也不是js结尾。
然后就是前面两个,其实两个都可以,我这里就直接用第二个了。
可以看到其data值后的对象结构,和我们前面观察的负载结构是一模一样的,所以这里data数据加密的代码就在这里了,也就是这里调用的P().encryptValue()函数,至于后面的JSON.stringify函数,是js本身自带的序列化函数,目的是将数据序列化为字符串。
所以这里的含义很简单,就是将原数据(对象或结构体)序列化为一个字符串,然后对这个字符串进行加密、编码之类的处理,最后的结果就是我们刚才看到的那一串字符串。
因此下一步就是看这个函数的内部实现是什么,最简单的方式就是直接复制这里的所有代码,并将其粘贴到vscode中:

然后鼠标放在其上,按F12,就会自动跳转到p函数所在的位置:

随后可以看到,这个p函数实际上是后面这个21开头的js文件内导出的d函数,因此下一步就是找到这个21开头的js文件:
再一次将它的代码复制到vscode中找到d函数:
直接使用vscode自带的搜素功能,从末尾开始搜,因为其最后一行才是导出函数的代码,于是很容易就能找到是be函数,然后直接鼠标放在其上,按F12进行跳转:
然后可以看到,be是一个很奇怪的一大段东西,尤其是这里Bp函数,看起来非常的奇怪。
但如果你继续跳转Bp函数,就会发现其内部并没有什么太多处理:
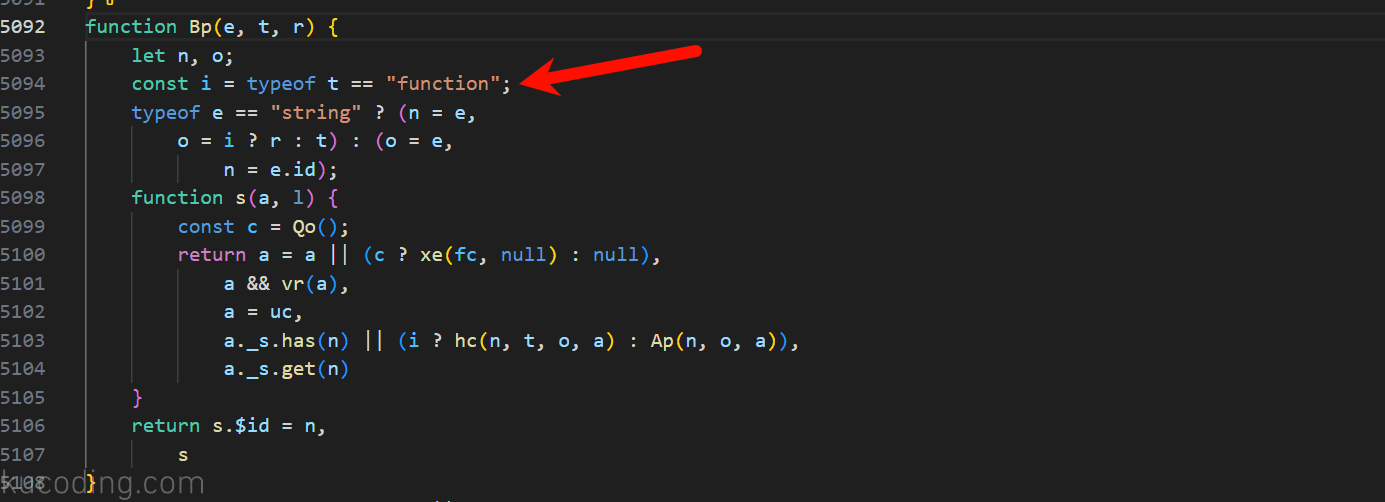
但当你看到它在判断传入的值类型是否为function时,就应该要有这样的推论,那就是它是一个功能函数、根据传入的值类型不同进行不同的处理,并不是我们需要的加密、解密的东西,因为加密解密对应的应该时字符串。
所以关键的代码并不在Bp函数本身,而在于传入Bp的参数,所以我们回到先前的函数调用位置,查看其第二个参数,可以发现其内部有着大量的函数定义。
但你翻到这个参数的末尾时,就会惊喜的发现,它返回了一系列函数,其中一个函数的名字就叫做encryptValue,这不就是我们外部调用的那个加密函数吗?

它就等于m函数,此时只需要将你的鼠标放在m变量上,就能看到加密函数的定义了。
并且只要你稍微留心一点,就会发现加密函数上方的cryptoValue,不就是解密的意思吗?
在js逆向过程中,一定要对一些字符串有敏锐度,比如这里的crypt,只要包含了它的,一般就对应着加密、解密操作,其完整单词为密码 cryption,加密是encryption、解密是decryption,
然后鼠标放在m与y上,按F12跳到对应的函数:
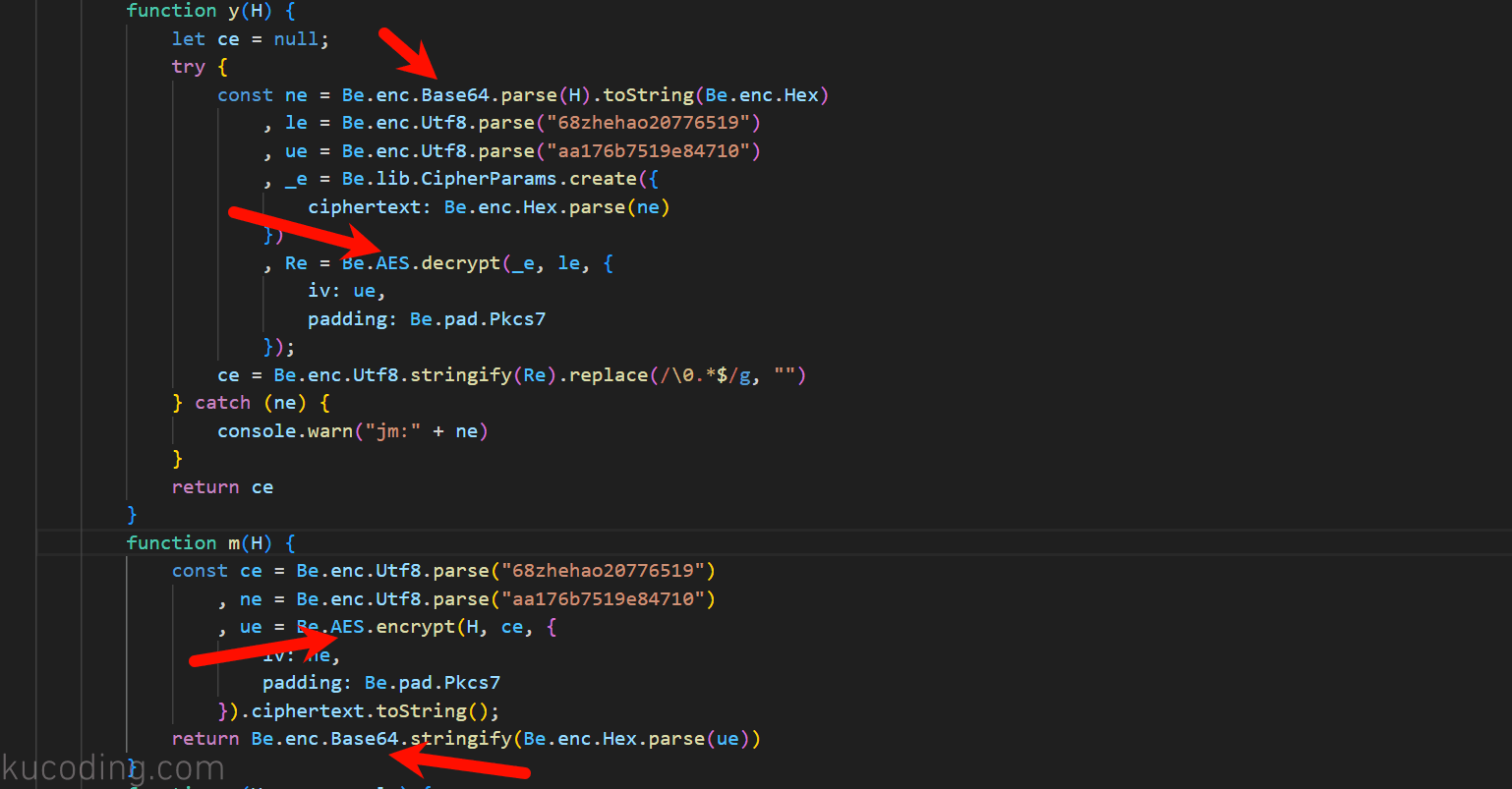
然后就能看到关键字AES与base64,其中base64前面说过,是一个非常通用的编码格式,而AES则是非常通用的加解密库。
并且可以明显看到这两个函数AES与base64的调用顺序相反,这不就正对应加密与解密过程吗?
有了这两个加密解密函数后,并不需要你自己去分析、使用python复现它,直接丢给ChatGPT,让它将这两个函数转换为Python版本即可。
以下便是我使用ChatGPT转换之后的结果:
from Crypto.Cipher import AES
from Crypto.Util.Padding import pad, unpad