一、前言
rust中的宏与C/C++中的宏是非常不一样的存在,C/C++中的宏仅仅只是简单的“文本替换”而已,而rust中的宏却可以被应用在“语法树”(token tree)上。
所谓“语法树”,是编译器根据该语言的语法规则、从你写的代码文件中所构建出来的一种树形结构,可以用于方便的分析代码语法,从而让编译器更加容易判断你的写的代码是否有错误、以及可能的修复方式等等。
这涉及到“编译原理”的相关理论知识,它是一门很难的课程,但好在我们并不需要自己开发语法分析器,所以是不需要去学习如何根据代码去生成一颗语法树的。
rust中的宏便是利用了rust编译器生成的这颗语法树来实现一些非常强大的功能,专业点来说,它实现了非常好的元编程操作方式。
二、基本使用
rust中一共提供了两种类型的宏:
- 声明式宏:比如
println!就是一个声明式宏,常被用来移除重复的代码,和函数功能有点像,不同之处在于它会将编译期间生成的代码复制到使用该宏的位置。 - 过程宏:允许让你直接操作rust代码的抽象语法树,可以提供一些非常高级的功能,常见的就是
#[drive(Debug)],这里的drive就是官方写的过程宏,可以让我们非常方便的实现某个trait。
1.声明式宏
首先是声明式宏的用法,它其实和rust中的match语法很像,使用的关键字是:macro_rules!。
虽然它没有“过程宏”强大,但其提供了非常容易使用的接口让我们可以快速的移除重复代码。
一个简单的声明式宏写法如下:
macro_rules! add {
// 类似于match
($a:expr,$b:expr) => {
{
//使用传入的变量生成代码
$a + $b
}
};
}
macro_rules!后面紧跟着的是宏的名字,然后就是宏的内容{}。
其中宏的内容其实和match非常像,你可以写多个类似()=>{}这样的语句分支,只有当宏根据参数匹配到合适的语句分支、才会去生成对应分支下的代码。
比如上面的代码中,我暂时只写了一个分支语句,该分支的参数为两个变量$a与$b,其类型为expr,表示这两个变量都是“表达式”。
注意:宏中的变量需要在前面添加$符号用于标识。
然后看到该分支语句中的内容,写了一个{},该{}内部就是让两个表达式相加。
使用方式很简单:
fn main() {
// 调用宏,此时$a=1,$b=2
add!(1, 2);
}
只需要在宏名后面添加!符号即可调用。
以上的代码在编译后,实际上是等价于下面这段代码:
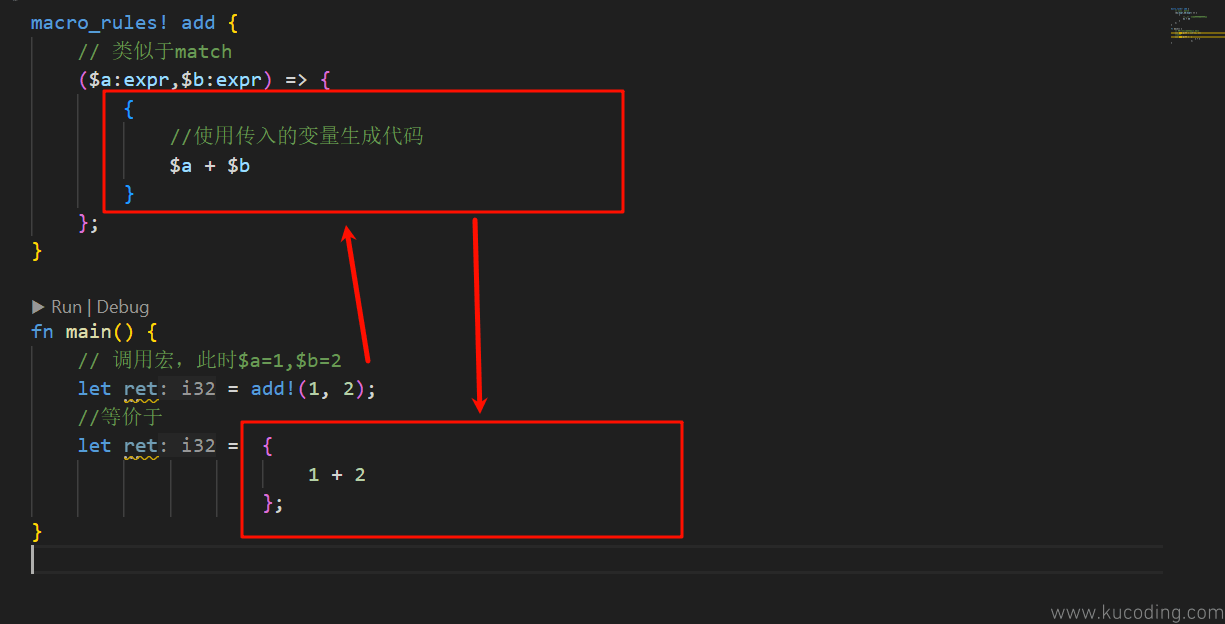
这么一对比,是不是就看出了其工作原理了?和C++中的宏相比,这里的声明式宏仅仅只是提供了更加高级的语法而已,本质上其实依旧是“替换”。
只不过注意这里用到了前面基础语法章节中提到的表达式概念,只要不加;,那大部分情况下它应该都可以被认为是表达式,而不是语句。
所以此时{}就有结果了,也就是1+2,因此才能让其为变量ret赋值。
rust中很多函数的最后一句省略了
return语句以及;,只放一个值在最后,和这里用的是一样的语法。
同时注意我前面说过,$a与$b的类型都是表达式,所以你完全可以这样调用:
let ret = add!(1 + 2, 2 + 3);
此时其展开后的的内容其实是:
let ret={
1+2+2+3
};
表达式类型expr是用的最多的,但同样还有很多其它的可选类型:
item:一个项,比如函数、结构、模块等。block:块(即语句块和/或表达式,由大括号包围)stmt:声明pat:一种模式expr:表达式ty:类型,比如u8、u16等等,一旦将它作为参数类型,那么你就需要传入这些类型作为变量。ident:标识符path:路径,指的是模块路径,比如std::mem、std::pathmeta:元项目,#[]和#![]属性里面的东西。tt:单个token树vis:可能为空的“可见性”限定符
更详细的介绍可以参考官方文档:Macros By Example。
然后下一步再来试试多分支的写法:
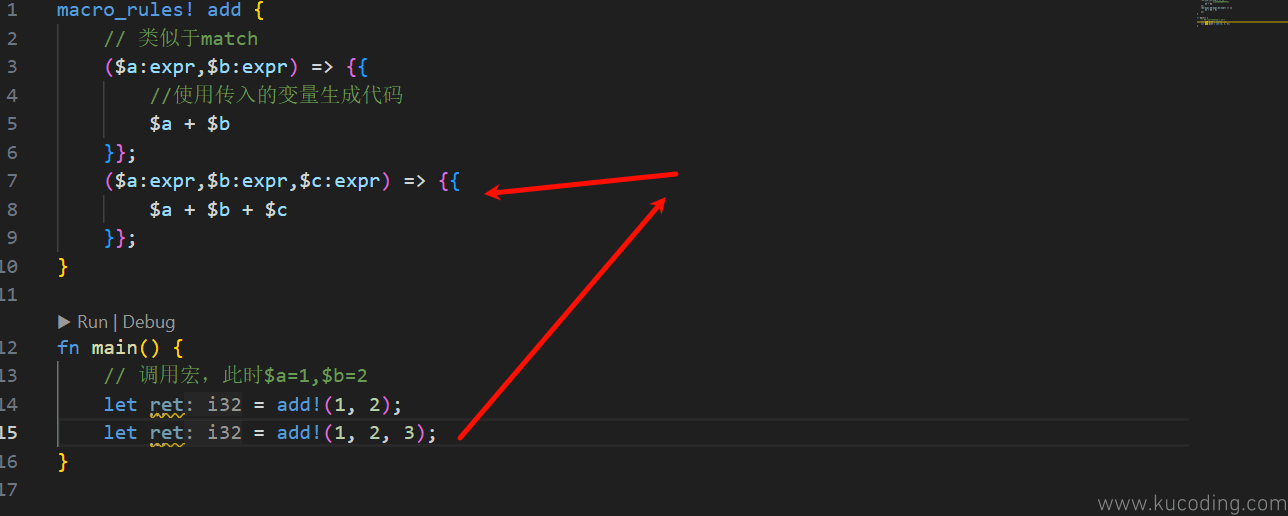
比如第二个分支用来求三个参数的和,此时你就可以用3个参数来调用该宏了。
对于这种需要适配不定数量参数的,这样挨个写分支也很麻烦,比如printfn宏就是你可以写入任意数量的参数都能处理。
这种就需要用到更复杂的匹配项了:
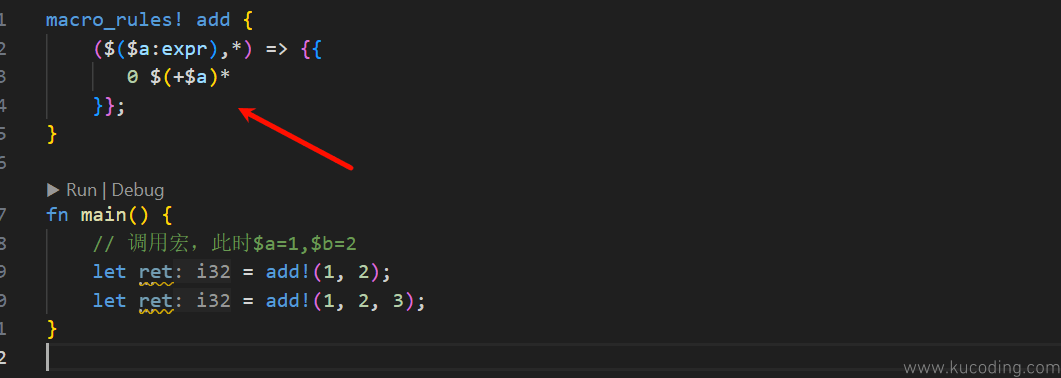
可以看到,此时虽然我只写了一个分支,但无论使用多少个参数调用都是可用的。
它的写法类似于正则表达式,你只需要把需要重复使用的变量用$()包裹起来,然后在其后面用,分割,再写上*即可代表0个或多个该类型的参数。
比如这里的$a:expr,我想让其重复0次或多次,那就使用$()将其包裹起来,其后紧跟,*。
此时在宏内部使用方式也变了,因为此时它不再单单指代一个变量,而是0个或无数个,所以需要定义其内每个变量的重复方式。
比如这里我定义的其重复方式是在每个变量前面添加符号+,也就是+$a,然后还需要让其不断重复被使用、应用到所有变量,所以还需要用$()*将其包裹。
因为所有符号+都是在变量前面,所以最前面还需要添加一个0。
此时如果调用add!(1,2),实际的效果就是:
{
0+1+2
}
除了使用*外,你还可以将其替换为+,代表一次或多次。
2.过程式宏
过程式宏相比于前面的声明式宏要强大的多,它允许你获取一段rust代码,然后你可以分析其结构、生成新的rust代码。
这相当于给我们提供了一种使用rust语言本身写rust代码的能力。
在我们平时用到的许多crate中,都可以看到其提供的一些用法:
- 派生宏:也就是最常见的
#[drive(Debug)写法,这种宏适用于结构体、枚举等结构,可以快速实现某个trait, - 属性宏:这个可能不怎么常见,但在某些库,比如clip,你在其示例文档中会看到相关的用法,可用于修改某些字段代码,比如结构体中的字段。
但同样的,它使用起来也要复杂的多,因为其原理是在编译期间去修改“代码”,也就是去操控、修改“语法树”。
比如当我们为自定义结构体写上#[drive(Debug)宏后,编译器在编译的时候就会调用相应的过程宏获取当前结构体代码,生成Debug所需要实现的代码,最后在编译之前将生成的代码插入到语法树中交给编译器去编译。
目前过程宏只能被定义在一个单独的crate中,而且这个crate还必须是一个lib类型。